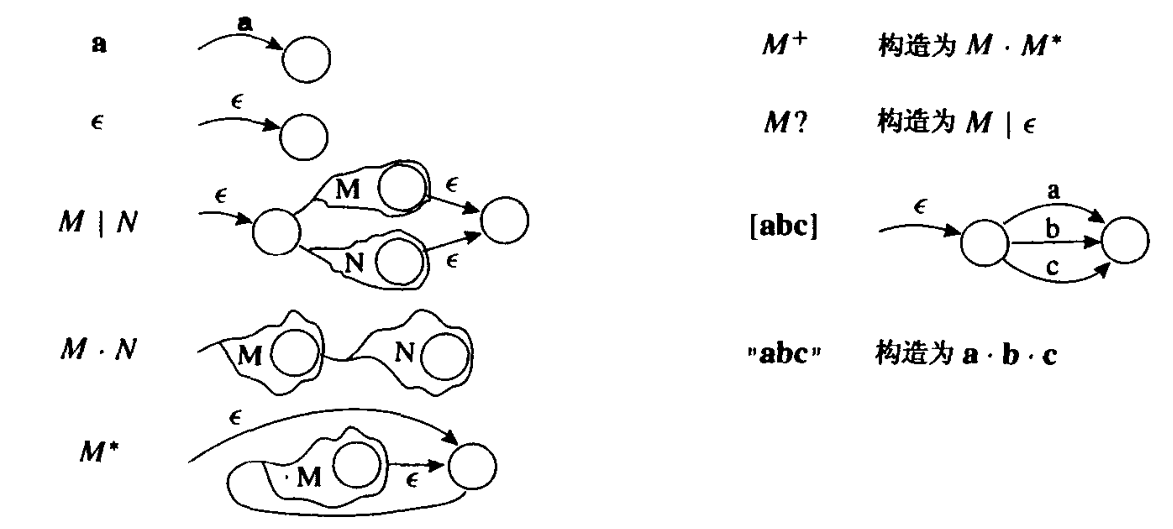
词法的(Lex-i-cal):与语言的单词或词汇有关,但有别于语言的文法和结构的。
词法分析器以字符流作为输入,生成一系列的名字、关键字和标点符号,同时抛弃单词之间的空白符和注释。程序中每一点都有可能出现空白符和注释;如果让语法分析器来处理它们就会使得语法分析过于复杂,这便是将词法分析从语法分析中分离出去的主要原因。词法分析并不很复杂,但是我们却使用能力强大的形式化方法和工具来实现它,因为类似的形式化方法对语法分析研究很有帮助,并且类似的工具还可以应用于编译器以外的其他领域。
2.1 词法单词
词法单词是字符组成的序列,它可以看成是程序设计语言的文法单位。程序设计语言的词法单词可以归类为有限的几组单词类型。例如,典型程序设计语言的一些单词类型为:
| 类型 | 例子 |
|---|---|
| ID | foo,n14,last |
| NUM | 10,00,515,082 |
| REAL | 66.1,.33,10.,1e6,2.2e - 10 |
| IF | if |
| COMMA | , |
| LPAREN | ( |
| RPAREN | ) |
IF、VOID、RETURN 等由字母字符组成的单词称为保留字(reserved word),在多数语言中,它们不能作为标识符使用。
非单词的例子:
| 类型 | 例子 |
|---|---|
| 注释 | /* Try again */ |
| 预处理命令 | #include <stdio.h>,#define NUMS 5, 6 |
| 宏 | NUMS |
| 空格符,制表符,换行符 | ,\lt,\n |
例如,对于下列程序:
float match0(char *s) /* find a zero */
{
if(!strncmp(s, "0,0", 3))
return 0;
}此法分析器将返回下列单词流:
FLOAT ID(match0) LPAREN CHAR STAR ID(s) RPAREN
LBRACE IF LPAREN BANG ID(strncmp) LPAREN ID(s)
COMMA STRING(0.0) COMMA NUM(3) RPAREN RPAREN
RETURN REAL(0.0) SEMI RBRACE EOF其中报告了每个单词的单词类型。这些单词中有一些(如标识符和文字常数)有语义值与之相连,因此,词法分析器还给出了除单词类型之外的附加信息。
我们可以用自然语言来描述一种语言的词法单词。例如,下面是对 C 或 Java 中标识符的一种描述:
标识符是字母和数字组成的序列,第一个字符必须是字母。下划线“_”视为字 母。大小写字母不同。如果经过若干单词分析后输入流已到达一个给定的字符,则下 一个单词将由有可能组成一个单词的最长字特串所组成。其中的空格符、制表符、换行符和注释都将被忽略,除非它们作为独立的一类单词。另外需要有某种空白符来分隔相邻的标识符、关键字和常数。
任何合理的程序设计语言都可以用来实现特定的词法分析器。但是我们将用正则表达式的形式语言来指明词法单词,用确定的有限自动机来实现词法分析器,并用数学的方法将两者联系起来。这样将得到一个简单且可读性更好的词法分析器。
2.2 正则表达式
我们说一种语言(language)是字符串组成的集合,字符串是符号(symbol)的有限序列。 符号本身来自有限字母表(alphabet)。
2.2.1 符号表示
Pascal 语言是所有组成合法 Pascal 程序的字符串的集合;素数语言是构成素数的所有十进制数字字符串的集合;C 语言保留字是 C 程序设计语言中不能作为标识符使用的所有字母数字字符串组成的集合。这三种语言中,前两种是无限集合,后一种是有限集合。在这三种语言中, 字母表都是 ASCII 字符集。
以这种方式谈论语言时,我们并没有给其中的字符串赋予任何含义,而只是企图确定每个 字符串是否属于其语言。 为了用有限的描述来指明这类(很可能是无限的)语言,我们将使用正则表达式(regular expression)表示法。每个正则表达式代表-一个字符串集合。
- 符号(symbol):对于语言字母表中的每个符号 $a$,正则表达式 $a$ 表示仅包含字符串 $a$ 的语言。
- 可选(alternation):对于给定的两个正则表达式 $M$ 和 $N$,可选操作符(
|)形成一个新的正则表达 $M~|~N$。如果一个字符串属于语言 $M$ 或者语言 $N$,则它属于语言 $M~|~N$。因 此,$a~|~b$ 组成的语言包含 $a$ 和 $b$ 这两个字符串。 - 联结(concatenation):对于给定的两个正则表达式 $M$ 和 $N$,联结操作符(
·)形成一个 新的正则表达式 $M·N$。如果一个字符串是任意两个字符串 $\alpha $ 和 $\beta$ 的联结,且 $\alpha$ 属于语言 $M$,$\beta$ 属于语言 $N$,则该字符串属于 $M·N$ 组成的语言。因此,正则表达式 $(a~|~b)·a$ 定义了一个包含两个字符串 $aa$ 和 $ba$ 的语言。 - $\epsilon$ (epsilon):正则表达式 $\epsilon$ 表示仅含一个空字符串的语言。因此,$(a·b)~|~\epsilon$ 示语言
{" ", "ab"}。 -
重复(repetition):对于给定的正则表达式 $M$,它的克林(Kleene)闭包是 \[M^*\]。如果一个字符串是由 $M$ 中的字符串经零至多次联结运算的结果,则该字符串属于 \[M^*\]。因此, \[((a~|~b)·a)^*\]表示无穷集合
{" ","aa", "ba", "aaaa", "baaa", "aaba", "baba", "aaaaaa", ...)。通过使用符号、可选、联结、闭包和克林闭包,我们可以规定与程序设计语言词法单词相 对应的
ASCII字符集。在书写正则表达式时,我们有时会省略联结操作符或 $\epsilon$ 符号,并假定克林闭包的优先级高于联结运算,联结运算的优先级高于可选运算,所以 $ab~|~c$ 表示 $(a·b)~|~c$,$(a~|~)$ 表 示 $(a~|~\epsilon)$。
2.2.2 二义性文法的处理
对于某些带有二义性的文法,例如 if18,应当将它看成是一个标识符,还是两个单词 if 和 8?字符串 " if 89" 是以一个标识符开头还是以一个保留字开头?$Lex$ 和其他类似的词法分析器使用了两条重要的消除二义性的规则:
- 最长匹配:初始输入子串中,取可与任何正则表达式匹配的那个最长的字符串作为下一个单词。
- 规则优先:对于一个特定的最长初始子串,第一个与之匹配的正则表达式决定了这个子串的单词类型。也就是说,正则表达式规则的书写顺序有意义。
因此,依据最长匹配规则,if8 是一个标识符;根据优先规则,if 是一个保留字。
2.3 有限自动机
用正则表达式可以很方便地指明词法单词,但我们还需要一种用计算机程序来实现的形式化方法。用有限自动机可以达到此目的。
有限自动机:有一个有限状态集合和一些从一个状态通向另一个状态的边,每条边上标记有一个符号;其中一个状态是初态,某些状态是终态。
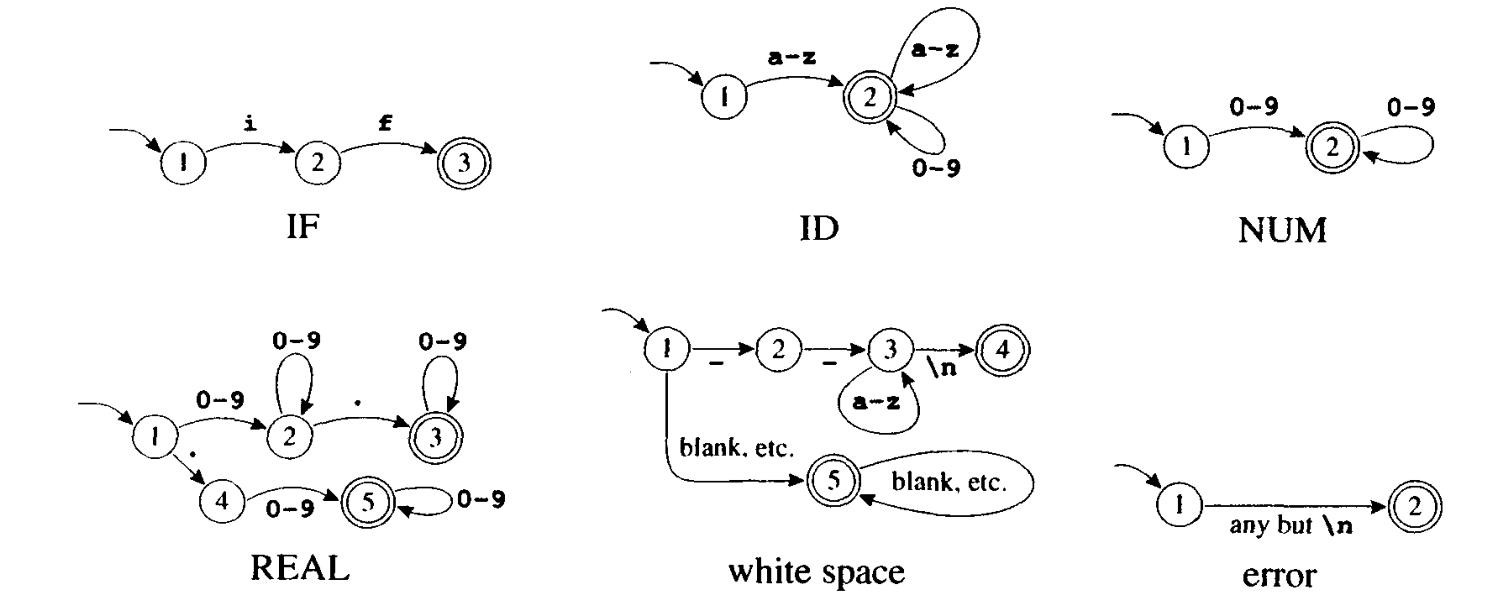
上图给出了一些有限自动机的例子。为了讨论方便我们给每个状态一个编号。每个例子中的初态都是编号为 1 的状态。标有多个字符的边是多条平行边的缩写形式;因此,在机器 ID 中,实际上有 26 条边从状态 1 通向状态 2,每条边用不同的字母标记。
在确定的有限自动机(DFA)中,不会有从同一状态出发的两条边标记有相同的符号。
DFA 以如下方式接收或拒绝一个字符串:
- 从初始状态出发,对于输入字符串中的每个字符,自动机都将沿着一条确定的边到达另一状态,这条边必须是标有输入字符的边。
- 对 $n$ 个字符的字符串进行了 $n$ 次状态转换后,如果自动机到达了一个终态,自动机将接收该字符串。
- 若到达的不是终态,或者找不到与输入字符相匹配的边,那么自动机将拒绝接收这个字符串。
- 由一个自 动机识别的语言是该自动机接收的字符串集合。
显然,在由自动机 ID 识别的语言中,任何字符串都必须以字母开头。任何单字母都能通至状态 2,因此单字母字符串是可被接收的字符串。从状态 2 出发,任何字母和数字都将重新回到状态 2,因此一个后跟任意个数字母和数字的字母也将被接收。
2.4 非确定有限自动机
非确定有限自动机 (NFA) 是一种需要对从一个状态出发的多条标有相同符号的边进行选择的自动机。它也可能存在标有 $\epsilon$(希腊字母)的边,这种边可以在不接收输入字符的情况下进行状态转换。
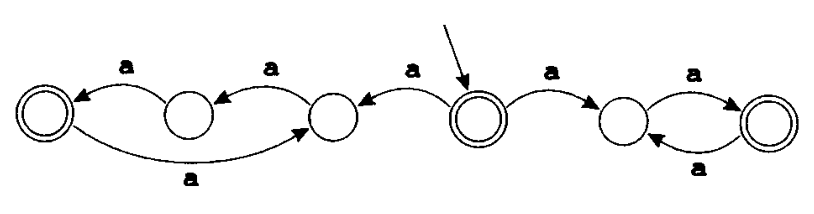
如上图,在初态时,根据输入的字母,自动机既可向左转换,也可向右转换。若选择了向左转换,则接收的是长度为 3 的倍数的字符串;若选择了向右转换,则接收的是长度为偶数的字符串。因此, 由这个 NFA 识别的语言是长度为 2 的倍数或 3 的倍数的所有由字母 a 组成的字符串的集合。
在第一次转换时,这个自动机必须选择走哪条路。如果存在着任何导致该字符申被接收的 可选择路径,那么自动机就必须接收该字符串。因此,自动机必须进行“猜测”,并且必须总是做出正确的猜测。
标有 $\epsilon$ 的边可以不使用输入中的字符。下面是接收同样语言的另一个 NFA:
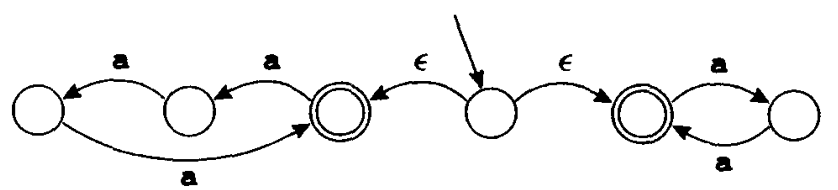
同样地,这个自动机必须决定选取哪一条 $\epsilon$ 边。若存在着一个状态,既有一些 $\epsilon$ 边,又有一些标有符号的边,则自动机可以选择接收一个输入符号(并沿着标有对应符号的边前进),或者 选择沿着 $\epsilon$ 边前进。
2.4.1 将正则表达式转换为 NFA
非确定的自动机是一个很有用的概念,因为它很容易将一个(静态的、说明性的)正则表达式转换成一个(可模拟的、准可执行的)NFA。 转换算法可以将任何一个正则表达式转换为有一个尾巴和一个脑袋的 NFA,它的尾巴即开始边,简称为尾;脑袋即末端状态,简称为头。
例如,单个符号的正则表达式 $a$ 转换成的 NFA 为:
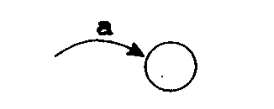
由 $a$ 和 $b$ 经联结运算而形成的正则表达式 $ab$ 对应的 NFA 是由两个 NFA 组合而成的,即将 $a$ 的头与 $b$ 的尾连接起来。由此得到的自动机有一个用 $a$ 标记的尾和一个从 $b$ 边进入的头。
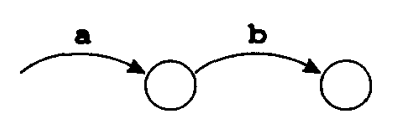
一般而言,任何一个正则表达式 $M$ 都有一个具有尾和头的 NFA:
我们可以归纳地定义正则表达式到 NFA 的转换。一个正则表达式或者是原语(单个符号或 $\epsilon$),或者是由多个较小的表达式组合而成。类似地,NFA 或者是基本元素,或者是由多个较小的NFA组合而成。
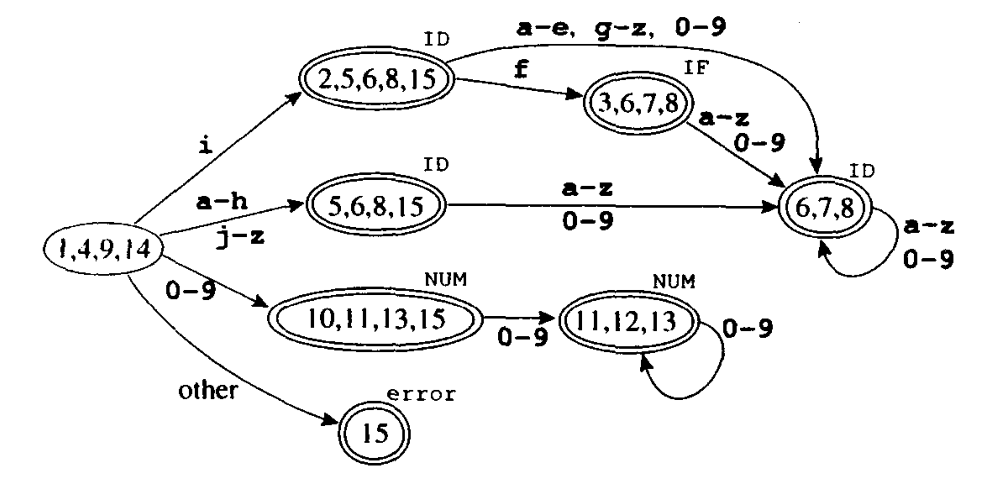
将正则表达式转换至 NFA ,我们利用单词 IF、ID、NUM 以及 error 的一些表达式来举例说明这种转换算法。每个表达式都转换成了一个 NFA,每个 NFA 的头是用不同单词类型标记的终态结点,并且每一个表达式的尾汇合成一个新的初始结点。由此得到的结果(在合并了某些等价的 NFA 状态之后)如下图所示:
2.4.2 将 NFA 转换为 DFA
用计算机程序实现确定的有限自动机(DFA)较容易。但实现 NFA 则要困难一些,因为大多数计算机都没有足够好的可以进行“猜测”的硬件。下面给出一个由四个正则表达式转换成的 NFA:
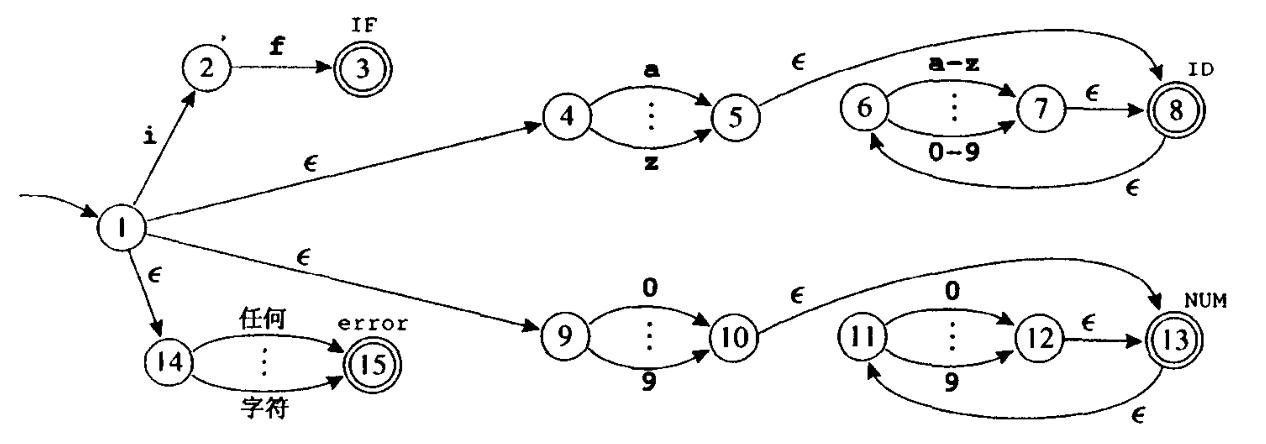
我们用一个字符串 "in" 来模拟,计算所有的 $\epsilon$ 闭包:
- 状态
1开始,替代猜测应采用哪个 $\epsilon$ 转换,此时NFA可能选择{1, 4, 9, 14}它们中的任何一个。 - 计算
{1}的 $\epsilon$ 闭包,显然,不接收输入中的第一个字符,就不可能到达其他状态,因此首先根据字符i来进行转换。 - 从状态
1可以到达状态2,从状态4可到达状态5,从 状态9则无处可去,而从状态14则可以到达状态15,由此得到状态集合{2, 5, 15}。 - 继续计算,从状态
5有一个 $\epsilon$ 转换至状态8,从状态8有一个 $\epsilon$ 转换至状态6。因此这个NFA一定属于状态集合{2, 5, 6, 8, 15}。 -
对于下一个输入字符 $n$,从状态
6可到达状态7,但状态2、5、8和15都无相应的转换。 因此得到状态集合{7},它的 $\epsilon$ 闭包是{6, 7, 8}。现在已到达字符串
"in"的末尾,在得到的可能状态集合中,状态8是终态,因此 $n$ 是一个ID单词。我们形式化地定义 $\epsilon$ 闭包如下。 令 $edge(s,c)$ 是从状态 $s$ 沿着标有 $c$ 的一条边可到达的所有
NFA状态的集合。对于状态集合$S$,$closure(S)$ 是从 $S$ 中的状态出发,无需接收任何字符,即只通过 $\epsilon$ 边便可到达的状态组成的集合。这种经过 $\epsilon$ 边的概念可用数学方式表述,即 $closure(S)$ 是满足如下条件的最小集合 $T$:
\[
T = S \cup \big(\bigcup_{x\in T}edge(s, \epsilon ) \big)
\]
上述表达式可以通过迭代算法求解:
\[
\begin{aligned}
&T \leftarrow S\\
&\text {repeat} &T'\leftarrow T\\
&&T\leftarrow T' \big( \bigcup_{s\in T'} \text {edge} (s,\epsilon) \big)\\
&\text {until} &T=T'
\end{aligned}
\]
上述算法可以模拟NFA的状态,接下来,设由NFA状态 $s_i,s_k,s_l$ 组成的集合 $d=\set{s_i,s_k,s_l}$ 中,从 $d$ 中的状态出发,并吃进输入符号 $c$,将到达NFA的一个新的状态集合,称这个集合为 $DFAedge(d,c)$:
\[
\text {DFAedge}(d,c) = \text {closure}\big( \bigcup_{s\in d} \text {edge}(s,c) \big)
\]
利用 $DFAedge(d,c)$ 可以更形式化地表示NFA算法,设初态为 $s_1$,输入字符串的字符为 $c_1,\dots c_k$,则算法表示为:
\[
\begin{aligned}
d\leftarrow & \text {closure}(\{s_1\})\\
\text for~i&\leftarrow 1~\text to~k\\
d&\leftarrow \text {DFAedge}(d,c_i)
\end{aligned}
\]
状态集合运算是代价很高的运算——对进行词法分析的源程序中的每一个字符都做这种运算几乎是不现实的。但是,预先计算出所有的状态集合却是有可能的。由NFA构造一个DFA,使得NFA的每一个状态集合都对应于DFA的一个状态。因为NFA的状态个数有限 ($n$ 个),所以DFA的状态个数也是有限的(至多为 $2^n$个)。
一旦有了 $\text{closure}$ 和 $\text {DFAedge}$ 的算法,就很容易构造出DFA。DFA的状态 $d$ ,就是 $\text{closure}(s_1)$,这同NFA模拟算法一样。抽象而言,如果 $d_j =\text{DFAedge}(d_i,c)$,则存在着一条从 $d_i$ 到 $d_j$ 的标记为 $c$ 的边,令 $\sum$ 是字母表。
\[
\begin{array}{l}
\text { states[0] } \leftarrow\{\} ; \quad \text { states[1] } \leftarrow \text { closure }\left(\left\{s_{1}\right\}\right) \\
p \leftarrow 1 ; \quad j \leftarrow 0 \\
\text { while } j \leq p \\
\quad \text { foreach } c \in \Sigma \\
\qquad e \leftarrow \text { DFAedge(states }[j], c) \\
\qquad \text { if } e=\operatorname{states}[i] \text { for some } i \leq p \\
\qquad \quad\text { then trans }[j, c\} \leftarrow i \\
\qquad \quad\text { else } p \leftarrow p+1 \\
\qquad \qquad \text { states }[p] \leftarrow e \\
\qquad \qquad \text { trans }[j, c] \leftarrow p \\
j \leftarrow j+1
\end{array}
\]
该算法不访问DFA的不可到达状态。因为原则上DFA有 $2^n$ 个状态, 但实际上我们一般找到的只有约 $n$ 个状态是从初态可到达的。这一点对避免DFA解释器的转换表出现指数级的膨胀很重要,因为这个转换表是编译器的一部分。由此我们对上述所给出的
NFA应用该DFA算法得到如下图所示自动机: