1.1 基本概念
程序设计语言源程序的执行基本有两种方式:
- 翻译:使用翻译程序,将源程序翻译成为低级语言目标程序,然后执行目标程序。
- 解释:使用解释程序,对源程序逐个语句边解释边执行。
编译器:可以阅读以某一种语言(源语言)编写的程序,并把该程序翻译成为一个等价的、用另一种语言(目标语言)编写的程序,即能够完成编译程序的软件系统。
解释器:是另一种常见的语言处理器,它并不通过翻译的方式生成目标程序。从用户的角度看,解释器直接利用用户提供的输入执行源程序中指定的操作。
解释程序:是高级语言翻译程序的一种,它将源语言书写的源程序作为输入,解释一句就提交给计算机执行一句,并不形成目标程序。
编译程序:把高级语言源程序作为输入,进行翻译转换,产生出机器语言的目标程序,然后让计算机去执行这个目标程序,得到计算结果。
编译程序与解释程序的区别:最大的区别在于:前者生成目标代码,而后者不生成。编译程序是一种翻译程序,它把高级语言所写的源程序翻译成等价的机器语言或汇编语言的目标程序。 解释程序也是一种翻译程序,它将源程序作为输入并执行它,边解释边执行。 它与编译程序的主要区别在于在解释程序执行的过程中不产生目标程序,而是按照源语言的定义解释执行源程序本身。
1.2 模块与接口
编译器的运行的各个阶段,由一至多个软件模块来实现。将编译器分解成这样的多个阶段是为了能够重用它的各种构件。例如,当要改变此编译器所生成的机器语言的目标机时,只要改变栈帧布局(Frame Layout)模块和指令选择(Instruction Selection)模块就够了。当要改变被编译的源语言时,则至多只需改变翻译(Translate)模块之前的模块就可以了,该编译器也可以在抽象语法(Abstract Syntax)接口处与面向语言的语法编辑器相连。
抽象语法(Abstract Syntax)、IR树(IR Tree)和汇编(Assem)之类的接口是数据结构的形式。例如语法分析动作阶段建立抽象语法数据结构,并将它传递给语义分析阶段。另一些接口是抽象数据类型:翻译接口是一组可由语义分析阶段调用的函数;单词符号(Token)接口是函数形式,分析器通过调用它而得到输人程序中的下一个单词符号。
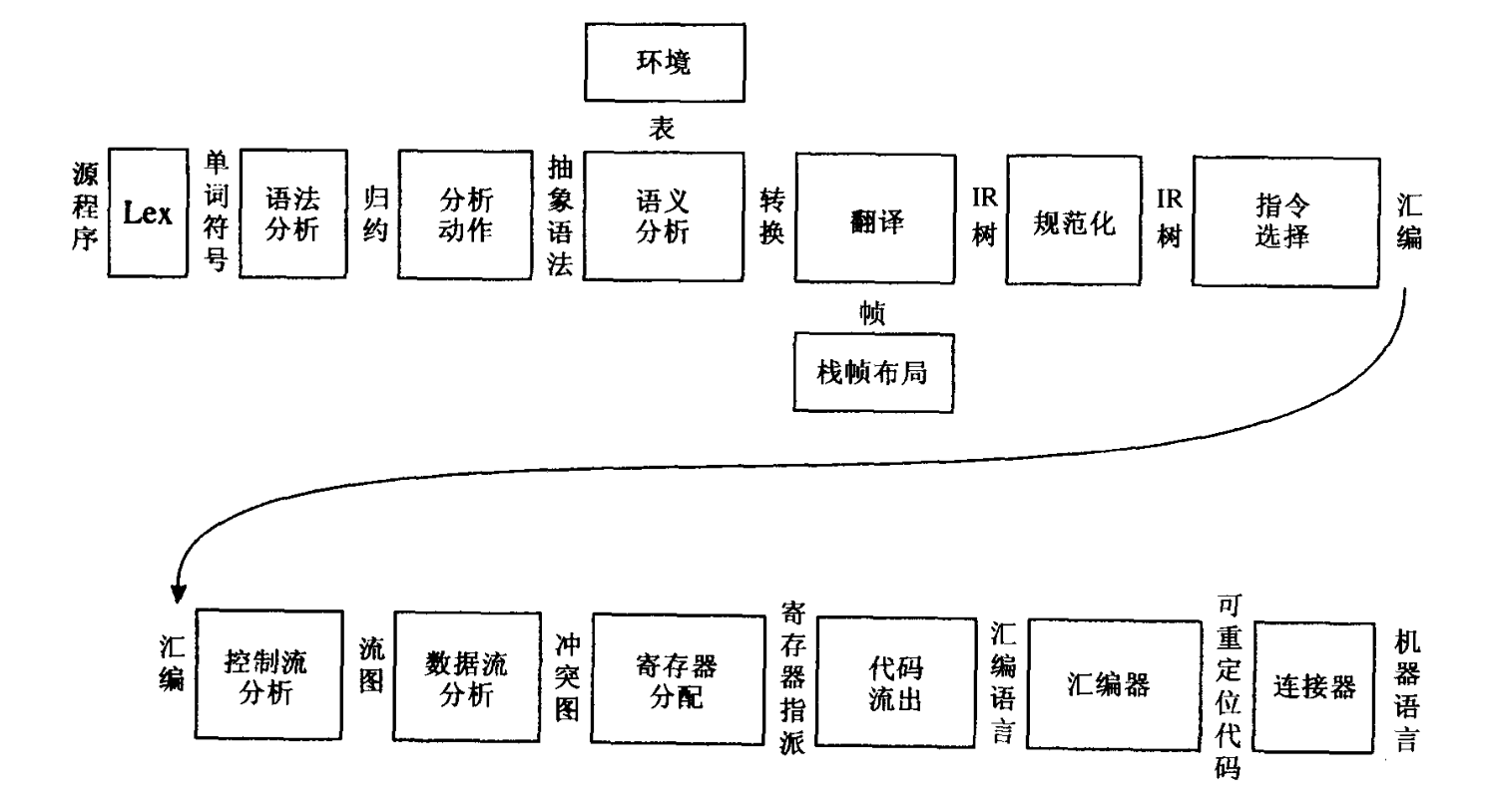
这种模块化设计是很多真实编译器的典型设计。但是,也有一些编译器把语法分析、语义分析、翻译和规范化合并成一个阶段,还有一些编译器将指令选择安排在更后一些的位置,并且将它与代码流出合并在一起。简单的编译器通常没有专门的控制流分析、数据流分析和寄存器分配。
1.3 编译过程
大致地,编译器编译一个语言源程序的过程如下:
| 顺序 | 阶段 | 描述 |
|---|---|---|
| 1 | 词法分析 | 将源文件分解为一个个独立的单词符号 |
| 2 | 语法分析 | 分析程序的短语结构 |
| 3 | 语义动作 | 建立每个短语对应的抽象语法树 |
| 4 | 语义分析 | 确定每个短语的含义,建立变量和其声明的关联,检查表达式的类型,翻译每个短语 |
| 5 | 栈帧布局 | 按机器要求的方式将变量、函数参数等分配于活跃记录(即栈帧)内 |
| 6 | 翻译 | 生成中间表示树(IR树),这是一种与任何特定程序设计语言和目标机体系结构无关的表示 |
| 7 | 规范化 | 提取表达式中的副作用,整理条件分支,以方便下一阶段的处理 |
| 8 | 指令选择 | 将IR树结点组合成与目标机指令相对应的块 |
| 9 | 控制流分析 | 分析指令的顺序并建立控制流图,此图表示程序执行时可能流经的所有控制流 数据流分析 收集程序变量的数据流信息,例如,活跃分析(liveness analysis)计算每一个变量仍需使用 其值的地点(即它的活跃点) |
| 10 | 寄存器分配 | 为程序中的每一个变量和临时数据选择一个寄存器,不在同一点活跃的两个变量可以共享同 一个寄存器 |
| 11 | 代码流出 | 用机器寄存器替代每一条机器指令中出现的临时变量名 |