本文最后更新于 558 天前,其中的信息可能已经有所发展或是发生改变。
1. 两数之和
- 哈希表
- 遍历数组,同时用
HashMap维护已出现过的数及其下标 - 若当前的数
nums[i]满足target - nums[i]曾经出现过,则直接返回 - 否则将其加入到哈希表中。
class Solution {
public int[] twoSum(int[] nums, int target) {
HashMap<Integer, Integer> st = new HashMap<>();
for (int i = 0; i < nums.length; i ++) {
int t = target - nums[i];
if (st.containsKey(t)) {
return new int[] {i, st.get(t)};
}
st.put(nums[i], i);
}
return null;
}
}class Solution {
public:
vector<int> twoSum(vector<int>& nums, int target) {
map<int, int> vis;
vector<int> ans;
for (int i = 0; i < nums.size(); i ++) {
int t = target - nums[i];
if (vis.find(t) != vis.end()) {
ans.push_back(i); ans.push_back(vis[t]);
return ans;
} else {
vis[nums[i]] = i;
}
}
return ans;
}
};49. 字母异位词分组
- 哈希表
- 遍历集合的 strs,对每个遍历到的字符串按照字典序进行排序
- 因此具有相同的字典序的字符串是同一组的异位词
- 利用哈希表用字典序映射对应组的下标
- 每次遍历将排序后的字符串在哈希表中找到其所属组的映射,然后加入该组即可
class Solution {
public List<List<String>> groupAnagrams(String[] strs) {
List<List<String>> ans = new ArrayList<>();
HashMap<String, Integer> vis = new HashMap<>();
int idx = 0;
for (String str : strs) {
char s[] = str.toCharArray();
Arrays.sort(s);
String st = new String(s);
if (vis.containsKey(st)) ans.get(vis.get(st)).add(str);
else {
List<String> cnt = new ArrayList<>();
cnt.add(str); ans.add(cnt);
vis.put(st, idx ++);
}
}
return ans;
}
}class Solution {
public:
vector<vector<string>> groupAnagrams(vector<string>& strs) {
vector<vector<string>> ans;
int idx = 0;
map<string, int> vis;
for (auto &p : strs) {
string t = p;
sort(t.begin(), t.end());
if (vis.find(t) != vis.end()) ans[vis[t]].push_back(p);
else {
vector<string> st;
st.push_back(p);
ans.push_back(st);
vis[t] = idx ++;
}
}
return ans;
}
};128. 最长连续序列
- 哈希
- 用 Set 对原数组内元素去重
- 遍历 Set,如果当前 num - 1 不存在于 Set 中,说明该 num 可能为连续序列的起始点
- 则不断判断 num ++ 是否存在于 Set,并更新最大长度
class Solution {
public int longestConsecutive(int[] nums) {
Set<Integer> st = new HashSet<>();
for (int num : nums) st.add(num);
int ans = 0;
for (int num : nums) {
if (!st.contains(num - 1)) {
int t = num;
int cnt = 1;
while (st.contains(t + 1)) {
t ++; cnt ++;
}
ans = Math.max(cnt, ans);
}
}
return ans;
}
}class Solution {
public:
int longestConsecutive(vector<int>& nums) {
set<int> st;
for (auto &p : nums) st.insert(p);
int ans = 0;
for (auto &p : st) {
if (st.find(p - 1) == st.end()) {
int t = p;
int cnt = 1;
while (st.find(t + 1) != st.end()) {
t ++, cnt ++;
}
ans = max(cnt, ans);
}
}
return ans;
}
};283. 移动零
- 双指针
- 用 j 表示当前为 0 的位置,i 表示走到的不为 0 的位置
- 如果 i 向后遍历到某个位置不为 0,则交换 nums[i] 和 nums[j]
- 交换后,j ++
- 初始化 j = i = 0,即使 nums[j] != 0,交换后的 j ++ 会后移到 0 的位置
class Solution {
public void moveZeroes(int[] nums) {
for (int i = 0, j = 0; i < nums.length; i ++) {
if (nums[i] != 0) {
int t = nums[i];
nums[i] = nums[j];
nums[j] = t;
j ++;
}
}
}
} class Solution {
public:
void moveZeroes(vector<int>& nums) {
for (int i = 0, j = 0; i < nums.size(); i ++) {
if (nums[i] != 0) {
swap(nums[i], nums[j]);
j ++;
}
}
}
};11. 盛最多水的容器
朴素版本:
- 模拟
- 以 i 为左边界,j 为右边界,遍历取 ans 最大值
- 若 height[i] * (j - i) < ans 说明 j 左移不存在比 ans 大的值,直接 break
class Solution {
public int maxArea(int[] height) {
int ans = 0;
for (int i = 0; i < height.length; i ++) {
for (int j = height.length - 1; j > i; j --) {
if (height[i] * (j - i) < ans) break;
ans = Math.max(ans, Math.min(height[i], height[j]) * (j - i));
}
}
return ans;
}
}优化:
- 双指针
- 以 l 为左边界,r 为右边界
- 取当 t = min(l, r),则若( l 向右移存在 height[l] > t)或 (r 向左移存在 height[r] > t)说明 ans 可能增大
class Solution {
public int maxArea(int[] height) {
int n = height.length;
int l = 0, r = n - 1;
int ans = Math.min(height[l], height[r]) * (r - l);
while (l < r) {
int t = Math.min(height[l], height[r]);
while (l < r && height[l] <= t) l ++; // 快速找到第一个满足条件的左边界
while (l < r && height[r] <= t) r --; // 同理找到右边界
ans = Math.max(ans, Math.min(height[r], height[l]) * (r - l)); // 更新答案
}
return ans;
}
}class Solution {
public:
int maxArea(vector<int>& height) {
int n = height.size();
int l = 0, r = n - 1;
int ans = min(height[l], height[r]) * (r - l);
while (l < r) {
int t = min(height[l], height[r]);
while (l < r && height[l] <= t) l ++;
while (l < r && height[r] <= t) r --;
ans = max(ans, min(height[l], height[r]) * (r - l));
}
return ans;
}
};15. 三数之和
- 双指针
- 首先对 nums 从小到大排序,使得其从小到大单调
- 遍历 nums[i],对于每个 nums[i],设 nums[i] 为三数之和中最小的数
- 利用双指针,在 nums[i] 的右边区间寻找符合条件的两个数
- 设左指针为 l = i + 1,右指针 r = nums.length - 1
- 若 nums[i] + nums[l] + nums[r] > 0 说明 r 需要向左移动,否则 l 需要向右移动
- 若 nums[i] + nums[l] + nums[r] == 0 说明是一个答案,需要记录
- 特别地,nums[i] > 0 的情况下,左边区间一定是大于 0 的,不存在任何答案
- 注意,在记录答案后需要不断移动 i,l 和 r,对相同的值去重
class Solution {
public List<List<Integer>> threeSum(int[] nums) {
Arrays.sort(nums);
List<List<Integer>> ans = new ArrayList<>();
for (int i = 0; i < nums.length - 1; i ++) {
if (nums[i] > 0) return ans;
int l = i + 1, r = nums.length - 1;
while (l < r) {
int t = nums[i] + nums[l] + nums[r];
if (t < 0) l ++;
else if (t > 0) r --;
else {
List<Integer> res = new ArrayList<>();
res.add(nums[i]); res.add(nums[l]); res.add(nums[r]);
ans.add(res);
while (l + 1 < r && nums[l] == nums[l + 1]) l ++;
while (r - 1 > l && nums[r] == nums[r - 1]) r --;
l ++; r --;
}
}
while(i + 1 < nums.length && nums[i] == nums[i + 1]) i ++;
}
return ans;
}
}class Solution {
public:
vector<vector<int>> threeSum(vector<int>& nums) {
vector<vector<int>> ans;
sort(nums.begin(), nums.end());
for (int i = 0; i < nums.size(); i ++) {
if (nums[i] > 0) return ans;
int l = i + 1, r = nums.size() - 1;
while (l < r) {
int t = nums[i] + nums[l] + nums[r];
if (t > 0) r --;
else if (t < 0) l ++;
else {
vector<int> res;
res.push_back(nums[i]); res.push_back(nums[l]); res.push_back(nums[r]);
ans.push_back(res);
while (l + 1 < r && nums[l] == nums[l + 1]) l ++;
while (r - 1 > l && nums[r] == nums[r - 1]) r --;
l ++, r --;
}
}
while (i + 1 < nums.size() && nums[i] == nums[i + 1]) i ++;
}
return ans;
}
};42. 接雨水
- 双指针
- 首先,用 idx 从左向右找到第一个不是 0 的位置,设其为蓄水池左边界
- 设 i 为蓄水池右边界,i 不断向右移动,如果 height[i] >= height[idx],说明后续的池子将以 height[i] 为左边界蓄水
- 此时,需要更新 idx 到 i 之间接到的雨水,设当前左边界高度为 t = height[idx],不断循环 ans += t - height[idx ++]
- 若 idx < height.length,说明存在某个位置 height[idx] 为最点,导致后续蓄水池不再以此边界更新,因此需要倒着再来一遍
class Solution {
public int trap(int[] height) {
int ans = 0;
int idx = 0;
while (idx + 1 < height.length && height[idx] == 0) idx ++;
for (int i = idx; i < height.length; i ++) {
if (height[i] >= height[idx]) {
int t = height[idx];
while(idx < i) {
ans += t - height[idx ++];
}
}
}
if (idx < height.length) { // 倒着同理再算一遍
int r = height.length - 1;
while (r - 1 > idx && height[r] == 0) r --;
for (int i = r; i >= idx; i --) {
if (height[i] >= height[r]) {
int t = height[r];
while (r > i) {
ans += t - height[r --];
}
}
}
}
return ans;
}
}class Solution {
public:
int trap(vector<int>& height) {
int ans = 0;
int idx = 0;
while (idx + 1 < height.size() && height[idx] == 0) idx ++;
for (int i = idx; i < height.size(); i ++) {
if (height[i] >= height[idx]) {
int t = height[idx];
while (idx < i) {
ans += t - height[idx ++];
}
}
}
if (idx < height.size()) {
int r = height.size() - 1;
while (r - 1 > idx && height[r] == 0) r --;
for (int i = r; i >= idx; i --) {
if (height[i] >= height[r]) {
int t = height[r];
while (r > i) {
ans += t - height[r --];
}
}
}
}
return ans;
}
};3. 无重复字符的最长子串
- 滑动窗口
- 设 vis 存储当前窗口中已经存在的元素
- 令 j 为窗口的左边界,i 为窗口的右边界
- 循环向左移动 i,每次都将 s.charAt(i) 加入 vis
- 如果 vis 中在加入之前已经存在 s.charAt(i),说明窗口中已经重复
- 因此需要不断缩小左边界,直到将某个 s.charAt(j) == s.charAt(i) 移出窗口
- 每次循环都要更新 vis 的最大长度即为答案
class Solution {
public int lengthOfLongestSubstring(String s) {
if (s.length() <= 1) return s.length();
Set<Character> vis = new HashSet<>();
int ans = 1;
for (int i = 0, j = 0; i < s.length(); i ++) {
if (vis.contains(s.charAt(i))) {
while (j <= i && vis.contains(s.charAt(i))) {
vis.remove(s.charAt(j ++));
}
}
vis.add(s.charAt(i));
ans = Math.max(ans, vis.size());
}
return ans;
}
}class Solution {
public:
int lengthOfLongestSubstring(string s) {
if (s.size() <= 1) return s.size();
int vis[200] = {0};
int ans = 1;
int idx = 0; // idx 记录窗口中已经存在的元素
for (int i = 0, j = 0; i < s.size(); i ++) {
if (vis[s[i]] == 1) {
while (j <= i && vis[s[i]] == 1) vis[s[j ++]] --, idx --;
}
vis[s[i]] ++; idx ++;
ans = max(ans, idx);
}
return ans;
}
};438. 找到字符串中所有字母异位词
- 滑动窗口
- 首先,用 res 数组统计 p 中每个字符的数量
- 设 j 为窗口的左边界,i 为窗口的右边界,用 vis 数组统计当前窗口中的每个字符数量
- 让 i 不断向右移动,每次移动都使得 vis[s.charAt(i)] ++
- 如果 i - j + 1 > p.length() 说明窗口过大,需要收缩左边界,同时将窗口 vis 统计的左边界字符移除一个,即 vis[s.charAt(j ++)] --;
- 如果 i - j + 1 == p.length(),则需要判断窗口内含每个字符数量和 p 是否相等,即循环判断 vis 和 res 每个字符数量即可
class Solution {
public List<Integer> findAnagrams(String s, String p) {
int[] res = new int[26];
List<Integer> ans = new ArrayList<>();
for (int i = 0; i < p.length(); i ++) res[p.charAt(i) - 'a'] ++;
int[] vis = new int[26];
for (int i = 0, j = 0; i < s.length(); i ++) {
vis[s.charAt(i) - 'a'] ++;
if (i - j + 1 > p.length()) vis[s.charAt(j ++) - 'a'] --;
if (i - j + 1 == p.length()) {
int flag = 0;
for (int k = 0; k < 26; k ++) {
if (res[k] != vis[k]) {
flag = 1; break;
}
}
if (flag == 0) ans.add(j);
}
}
return ans;
}
}class Solution {
public:
vector<int> findAnagrams(string s, string p) {
int res[26] = {0}, vis[26] = {0};
vector<int> ans;
for (auto op : p) res[op - 'a'] ++;
for (int i = 0, j = 0; i < s.size(); i ++) {
vis[s[i] - 'a'] ++;
if (i - j + 1 > p.size()) vis[s[j ++] - 'a'] --;
if (i - j + 1 == p.size()) {
bool flag = 1;
for (int k = 0; k < 26; k ++) {
if (vis[k] != res[k]) {
flag = 0; break;
}
}
if (flag) ans.push_back(j);
}
}
return ans;
}
};560. 和为 K 的子数组
- 前缀和
- 遍历 nums,用 cnt += nums[i] 记录前 i 个元素的和及其数量
- 判断若之前已经存在前缀和的值为 cnt - k,说明存在连续的某个区间符合条件
- 答案为这个值的前缀和数量相加
class Solution {
public int subarraySum(int[] nums, int k) {
int ans = 0, cnt = 0;
HashMap<Integer, Integer> vis = new HashMap<>();
vis.put(0, 1);
for (int i = 0; i < nums.length; i ++) {
cnt += nums[i];
if (vis.containsKey(cnt - k)) {
ans += vis.get(cnt - k);
}
vis.put(cnt, vis.getOrDefault(cnt, 0) + 1);
}
return ans;
}
}class Solution {
public:
int subarraySum(vector<int>& nums, int k) {
int ans = 0, cnt = 0;
map<int, int> vis;
vis[0] = 1;
for (auto p : nums) {
cnt += p;
ans += vis[cnt - k];
vis[cnt] ++;
}
return ans;
}
};239. 滑动窗口最大值
- 优先队列
- 利用优先队列存储当前窗口中的元素
- 用 Pair 对值和下标排序,优先最大的值,其次最小的下标
- 每次遍历,将窗口的右边界加入优先队列
- while 检查优先队列的队头,将下标超出窗口范围的值出队
- 对头元素即为当前窗口中的最大值
class Solution {
public int[] maxSlidingWindow(int[] nums, int k) {
int[] ans = new int[nums.length - k + 1];
PriorityQueue<Pair<Integer, Integer>> st = new PriorityQueue<>((a, b) ->
a.getKey().equals(b.getKey()) ? b.getValue() - a.getValue() : b.getKey() - a.getKey()
);
for (int i = 0; i < k; i ++) st.offer(new Pair<Integer, Integer>(nums[i], i));
ans[0] = st.peek().getKey();
int idx = 1;
for (int i = k; i < nums.length; i ++) {
st.offer(new Pair<Integer, Integer>(nums[i], i));
while (st.peek().getValue() <= i - k) st.poll();
ans[idx ++] = st.peek().getKey();
}
return ans;
}
}class Solution {
public:
vector<int> maxSlidingWindow(vector<int>& nums, int k) {
priority_queue<pair<int, int>> st;
for (int i = 0; i < k; i ++) st.push({nums[i], i});
vector<int> ans;
ans.push_back(st.top().first);
for (int i = k; i < nums.size(); i ++) {
st.push({nums[i], i});
while (st.top().second <= i - k) st.pop();
ans.push_back(st.top().first);
}
return ans;
}
};76. 最小覆盖子串
- 滑动窗口
- 用 vis 数组记录 t 中字符的种类及其数量
- 设 j 为最短子串的左边界,i 为最短子串的右边界
- i 不断向右移动,用 res 记录当前子串 j ~ i 中包含的字符种类及其数量
- 每次判断 res[s.charAt(j)] 的数量是否大于 vis[s.charAt(j)]
- 如果大于,则说明已经重复,应该收缩左边界使得子串的长度为最小
- 判断符合题意的条件为:res 中的字符种类及其数量 >= vis 中的字符种类及其数量
class Solution {
public String minWindow(String s, String t) {
int[] vis = new int[200];
for (int i = 0; i < t.length(); i ++) vis[t.charAt(i)] ++;
int[] res = new int[200];
String ans = "";
for (int i = 0, j = 0; i < s.length(); i ++) {
res[s.charAt(i)] ++;
while (res[s.charAt(j)] > vis[s.charAt(j)] && j < i) res[s.charAt(j ++)] --;
int flag = 1;
for (int k = 'A'; k <= 'z'; k ++) {
if (res[k] < vis[k]) {
flag = 0; break;
}
}
if (flag == 1) {
if (ans.length() == 0 || ans.length() > i - j + 1) ans = s.substring(j, i + 1);
}
}
return ans;
}
}class Solution {
public:
string minWindow(string s, string t) {
int vis[200] = {0};
for (auto p : t) vis[p] ++;
int res[200] = {0};
string ans = "";
for (int i = 0, j = 0; i < s.size(); i ++) {
res[s[i]] ++;
while (res[s[j]] > vis[s[j]] && j < i) res[s[j ++]] --;
bool flag = 1;
for (int k = 'A'; k <= 'z'; k ++) {
if (res[k] < vis[k]) {
flag = 0; break;
}
}
if (flag) {
if (ans == "" || ans.size() > i - j + 1) ans = s.substr(j, i - j + 1);
}
}
return ans;
}
};53. 最大子数组和
- 前缀和
- 和 560 的思路很像,用 cnt 记录 0 到当前位置的前缀和
- 用 res 记录之前前缀和的最小值
- 若使得连续的子数组和最大,则为 Math.max(ans, cnt - res)
class Solution {
public int maxSubArray(int[] nums) {
int res = 0;
int ans = Integer.MIN_VALUE;
int cnt = 0;
for (int i = 0; i < nums.length; i ++) {
cnt += nums[i];
ans = Math.max(ans, cnt - res);
res = Math.min(cnt, res);
}
return ans;
}
}class Solution {
public:
int maxSubArray(vector<int>& nums) {
int ans = -0x3f3f3f3f;
int res = 0;
int cnt = 0;
for (int i = 0; i < nums.size(); i ++) {
cnt += nums[i];
ans = max(ans, cnt - res);
res = min(res, cnt);
}
return ans;
}
};56. 合并区间
- 区间合并板子题
- 首先对每个子区间的左端点从小到大排序
- 设正在合并中区间两端分别为 l 和 r,初始化为第一个区间的端点
- 遍历排序后的区间,若
r <= intervals[i][1]说明可以进行合并,更新r = intervals[i][1] - 否则说明无法继续向后合并,将当前区间
[l, r]加入答案,重置l = intervals[i][0], r = intervals[i][1]
class Solution {
public int[][] merge(int[][] intervals) {
Arrays.sort(intervals, (o1, o2) -> o1[0] - o2[0]);
List<int[]> ans = new ArrayList<>();
int l = intervals[0][0], r = intervals[0][1];
for (int i = 1; i < intervals.length; i ++) {
if (r >= intervals[i][0]) r = Math.max(r, intervals[i][1]);
else {
ans.add(new int[]{l, r});
l = intervals[i][0];
r = intervals[i][1];
}
}
ans.add(new int[]{l, r});
return ans.toArray(new int[ans.size()][]);
}
}class Solution {
public:
vector<vector<int>> merge(vector<vector<int>>& intervals) {
vector<pair<int, int>> st;
for (auto p : intervals) st.push_back({p[0], p[1]});
sort(st.begin(), st.end());
vector<vector<int>> ans;
int l = st[0].first, r = st[0].second;
for (int i = 1; i < st.size(); i ++) {
if (r >= st[i].first) r = max(r, st[i].second);
else {
ans.push_back({l, r});
l = st[i].first, r = st[i].second;
}
}
ans.push_back({l, r});
return ans;
}
};189. 轮转数组
- 模拟
- 先反转整个数组
- 然后分别反转 0 ~ k,和 k ~ nums.length 个元素
class Solution {
public void rotate(int[] nums, int k) {
k %= nums.length;
reverse(nums, 0, nums.length);
reverse(nums, 0, k);
reverse(nums, k, nums.length);
}
private void reverse(int[] nums, int l, int r) {
r --;
while (l < r) {
int t = nums[l];
nums[l ++] = nums[r];
nums[r --] = t;
}
}
}class Solution {
public:
void rotate(vector<int>& nums, int k) {
k %= nums.size();
reverse(nums.begin(), nums.end());
reverse(nums.begin(), nums.begin() + k);
reverse(nums.begin() + k, nums.end());
}
};238. 除自身以外数组的乘积
- 前缀积(?
- 对于每个 nums[i],用 ans[i] 维护其左侧不包含 nums[i] 的元素的前缀积
- 即,对于 ans[i],表示为 nums[0] nums[1] ... * nums[i - 1]
- 那么,以同样的方式反过来再求一遍后缀积,然后把后缀积和前缀积相乘即为答案
- 对于后缀积,从 nums[nums.length - 2] 开始计算
class Solution {
public int[] productExceptSelf(int[] nums) {
int[] ans = new int[nums.length];
ans[0] = 1;
for (int i = 1; i < nums.length; i ++) {
ans[i] = ans[i - 1] * nums[i - 1];
}
int cnt = 1;
for (int i = nums.length - 2; i >= 0; i --) {
cnt *= nums[i + 1];
ans[i] *= cnt;
}
return ans;
}
}class Solution {
public:
vector<int> productExceptSelf(vector<int>& nums) {
vector<int> ans(nums.size());
ans[0] = 1;
for (int i = 1; i < nums.size(); i ++) {
ans[i] = ans[i - 1] * nums[i - 1];
}
int cnt = 1;
for (int i = nums.size() - 2; i >= 0; i --) {
cnt *= nums[i + 1];
ans[i] *= cnt;
}
return ans;
}
};41. 缺失的第一个正数
- 模拟
- 将数组本身视作哈希表
- 首先遍历整个数组,将所有 nums[i] <= 0 和 nums[i] > n 的数变为 nums[i] = n + 1,因为超过范围的数一定不存在该哈希表中
- 第二次遍历数组,对于 nums[i] 取其绝对值 t = Math.abs(nums[i]),如果 t <= n,说明这个值在哈希表中,将 nums[t - 1] 位置更新为 nums[t - 1] = - Math.abs(nums[t - 1])
- 这样做的原因是:nums[i] 为负数,说明 i + 1 数存在过,但是 nums[i] 的绝对值对应的下标不变
- 在第二次遍历完成后,出现过的数其数值下标的对应位置的值全部为负数,即对于 x 若出现过,则 nums[x] < 0
- 因此再次遍历数组,第一个找到的大于 0 的值的下标 i + 1 即为未出现过的第一个正数
class Solution {
public int firstMissingPositive(int[] nums) {
int n = nums.length;
for (int i = 0; i < n; i ++) if (nums[i] > n || nums[i] <= 0) nums[i] = n + 1;
for (int i = 0; i < n; i ++) {
int t = Math.abs(nums[i]);
if (t <= n) nums[t - 1] = - Math.abs(nums[t - 1]);
}
for (int i = 0; i < n; i ++) {
if (nums[i] > 0) return i + 1;
}
return n + 1;
}
}class Solution {
public:
int firstMissingPositive(vector<int>& nums) {
int n = nums.size();
for (int i = 0; i < n; i ++) if (nums[i] > n || nums[i] <= 0) nums[i] = n + 1;
for (int i = 0; i < n; i ++) {
int t = abs(nums[i]);
if (t <= n) nums[t - 1] = - abs(nums[t - 1]);
}
for (int i = 0; i < n; i ++) {
if (nums[i] > 0) return i + 1;
}
return n + 1;
}
};73. 矩阵置零
- 哈希
- 用两个 Set 分别存储需要置为 0 的横坐标和纵坐标
- 之后分别遍历两个 Set,对其标记的坐标循环置零即可
class Solution {
public void setZeroes(int[][] matrix) {
HashSet<Integer> x = new HashSet<>();
HashSet<Integer> y = new HashSet<>();
for (int i = 0; i < matrix.length; i ++) {
for (int j = 0; j < matrix[i].length; j ++) {
if (matrix[i][j] == 0) {
x.add(i); y.add(j);
}
}
}
for (Integer p : x) {
for (int j = 0; j < matrix[0].length; j ++) matrix[p][j] = 0;
}
for (Integer p : y) {
for (int i = 0; i < matrix.length; i ++) matrix[i][p] = 0;
}
}
}class Solution {
public:
void setZeroes(vector<vector<int>>& matrix) {
set<int> x, y;
for (int i = 0; i < matrix.size(); i ++) {
for (int j = 0; j < matrix[i].size(); j ++) {
if (matrix[i][j] == 0) {
x.insert(i); y.insert(j);
}
}
}
for (auto p : x) {
for (int j = 0; j < matrix[0].size(); j ++) matrix[p][j] = 0;
}
for (auto p : y) {
for (int i = 0; i < matrix.size(); i ++) matrix[i][p] = 0;
}
}
};54. 螺旋矩阵
- 模拟
- 偏移量数组,标记已经走过的位置
- 每次移动判断是否在矩阵范围内,且没有走过
- 否则改变方向,和偏移量数组的偏移值相照应
class Solution {
public List<Integer> spiralOrder(int[][] matrix) {
int n = matrix.length, m = matrix[0].length;
boolean[][] vis = new boolean[n][m];
int[] dx = new int[]{0, 1, 0 , -1}, dy = new int[]{1, 0, -1, 0};
int l = 0, r = 0, dr = 0;
List<Integer> ans = new ArrayList<>();
for (int i = 0; i < n * m; i ++) {
ans.add(matrix[l][r]);
vis[l][r] = true;
int x = l + dx[dr], y = r + dy[dr];
if (x < 0 || x >= n || y < 0 || y >= m || vis[x][y]) {
dr = (dr + 1) % 4;
}
l += dx[dr]; r += dy[dr];
}
return ans;
}
}class Solution {
public:
vector<int> spiralOrder(vector<vector<int>>& matrix) {
int dx[] = {0, 1, 0, -1}, dy[] = {1, 0, -1, 0};
set<pair<int, int>> st;
int dr = 0, n = matrix.size(), m = matrix[0].size();
vector<int> ans;
int l = 0, r = 0;
for (int i = 0; i < n * m; i ++) {
ans.push_back(matrix[l][r]);
st.insert({l, r});
int x = l + dx[dr], y = r + dy[dr];
if (x < 0 || x >= n || y < 0 || y >= m || st.find({x, y}) != st.end()) {
dr = (dr + 1) % 4;
}
l += dx[dr], r += dy[dr];
}
return ans;
}
};48. 旋转图像
- 矩阵转置
- 用线性代数的知识,先将矩阵转置,再翻转即可
- 将矩阵 $A$ 的行换成同序数的列得到的新的矩阵,叫做 $A$ 的转置矩阵,记作: $A^T$。

- 转置运算公式:
)
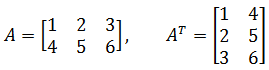
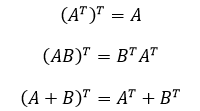
class Solution {
public void rotate(int[][] matrix) {
int n = matrix.length;
// 先进行矩阵的转置操作
for (int i = 0; i < n; i ++) {
for (int j = i; j < n; j ++) {
int temp = matrix[i][j];
matrix[i][j] = matrix[j][i];
matrix[j][i] = temp;
}
}
// 再进行每行的翻转操作
for (int i = 0; i < n; i ++) {
for (int j = 0; j < n / 2; j ++) {
int temp = matrix[i][j];
matrix[i][j] = matrix[i][n - 1 - j];
matrix[i][n - 1 - j] = temp;
}
}
}
}class Solution {
public:
void rotate(vector<vector<int>>& matrix) {
int n = matrix.size();
for (int i = 0; i < n; i ++) {
for (int j = i; j < n; j ++) {
swap(matrix[i][j], matrix[j][i]);
}
}
for (int i = 0; i < n; i ++) {
for (int j = 0; j < n / 2; j ++) {
swap(matrix[i][j], matrix[i][n - 1 - j]);
}
}
}
};240. 搜索二维矩阵 II
- 二分
- 由于矩阵的每一行都是单调递增的
- 因此遍历矩阵的每一行,逐行二分即可
class Solution {
public boolean searchMatrix(int[][] matrix, int target) {
int n = matrix.length, m = matrix[0].length;
for (int i = 0; i < n; i ++) {
int l = 0, r = m - 1;
while (l <= r) {
int mid = (l + r) >> 1;
if (matrix[i][mid] == target) return true;
if (matrix[i][mid] < target) l = mid + 1;
else r = mid - 1;
}
}
return false;
}
}class Solution {
public:
bool searchMatrix(vector<vector<int>>& matrix, int target) {
int n = matrix.size(), m = matrix[0].size();
for (int i = 0; i < n; i ++) {
int l = 0, r = m - 1;
while (l <= r) {
int mid = (l + r) >> 1;
if (matrix[i][mid] == target) return 1;
if (matrix[i][mid] < target) l = mid + 1;
else r = mid - 1;
}
}
return 0;
}
};160. 相交链表
- 分别遍历两个链表
- 若 a 先到达链表尾部,则使得 a = headB 开始重新遍历
- 若 b 先到达链表尾部,则使得 b = headA 开始重新遍历
- 当 a == b 时,说明要么两者遍历到了相交的节点,或者说明同时遍历到了链表的尾部节点
public class Solution {
public ListNode getIntersectionNode(ListNode headA, ListNode headB) {
if (headA == null || headB == null) return null;
ListNode a = headA, b = headB;
while (a != b) {
a = (a == null ? headB : a.next);
b = (b == null ? headA : b.next);
}
return a;
}
}class Solution {
public:
ListNode *getIntersectionNode(ListNode *headA, ListNode *headB) {
if (headA == nullptr || headB == nullptr) return nullptr;
ListNode *a = headA, *b = headB;
while (a != b) {
a = (a == nullptr ? headB : a -> next);
b = (b == nullptr ? headA : b -> next);
}
return a;
}
};206. 反转链表
- 设节点 r 为当前节点,其前一个节点为 l
- 由于翻转后需要保留下一个需要翻转的节点的指向,因此用 t 暂存
- 则翻转的过程为:
- 令节点 t 指向 r 的后一个节点,即 t = r.next
- 令当前节点指向它的前一个节点,即令 r 指向 l,r.next = l
- 此时,当前节点已经翻转完成,需要将 l 和 r 向后移动,翻转下一个节点
- 因此,需要对 l 和 r 进行更新:
- 令 l 为下一个需要翻转的节点的前一个节点,即之前翻转过的节点 r,l = r
- 令 r 为下一个需要翻转的节点,即 l 的下一个节点,r = t
- 注意需要先更新 l 才能更新 r,否则 l 会丢失
class Solution {
public ListNode reverseList(ListNode head) {
ListNode l, r, t;
l = null; r = head;
while (r != null) {
t = r.next;
r.next = l;
l = r;
r = t;
}
return l;
}
}class Solution {
public:
ListNode* reverseList(ListNode* head) {
ListNode *l, *r, *t;
r = head, l = nullptr;
while (r != nullptr) {
t = r -> next;
r -> next = l;
l = r;
r = t;
}
return l;
}
};234. 回文链表
- 首先找到链表中点
- 将后半部分链表进行翻转
- 同时遍历前后两端链表,判断对应的节点值是否相等
class Solution {
public boolean isPalindrome(ListNode head) {
int len = 0;
for (ListNode i = head; i != null; i = i.next) len++;
if (len == 1) return true; // 单节点链表自然是回文
len = (len + 1) >> 1; // 找到中点(对于偶数长度,向上取整)
ListNode l = head, r, t;
for (int i = 0; i < len - 1; i ++) l = l.next;
r = l.next; // r从中点的下一个节点开始
l.next = null; // 断开链表的前半部分和后半部分
// 反转链表后半部分
while (r != null) {
t = r.next;
r.next = l;
l = r;
r = t;
}
// 对比前半部分和反转后的后半部分
ListNode p = head, q = l;
for (int i = 0; i < len; i ++) {
if (p.val != q.val) return false;
p = p.next; q = q.next;
}
return true;
}
}class Solution {
public:
bool isPalindrome(ListNode* head) {
int len = 0;
for (ListNode *i = head; i != nullptr; i = i -> next) len ++;
if (len == 1) return true;
len = (len + 1) >> 1;
ListNode *l = head, *r, *t;
for (int i = 0; i < len - 1; i ++) l = l -> next;
r = l -> next;
l -> next = nullptr;
while (r != nullptr) {
t = r -> next;
r -> next = l;
l = r;
r = t;
}
ListNode *p = head, *q = l;
for (int i = 0; i < len; i ++) {
if (p -> val != q -> val) return 0;
p = p -> next, q = q -> next;
}
return 1;
}
};141. 环形链表
- 一个投机取巧的方案:
- 数据范围节点的数量不超过 $10^4$,因此遍历链表,循环计超过 1e4 + 1 次说明存在环
- 正解:
- 利用快慢指针进行判断
- 令快指针每次移动两个单位,满指针每次移动一个单位
- 若链表存在环,则在慢指针进入到环进行循环时,一定能和快指针相遇
public class Solution {
public boolean hasCycle(ListNode head) {
int len = 0;
for (ListNode i = head; i != null; i = i.next) {
len ++;
if (len > 1e4 + 10) return true;
}
return false;
}
}public class Solution {
public boolean hasCycle(ListNode head) {
if (head == null || head.next == null) return false;
ListNode a = head, b = head.next;
while (a != b) {
// 为 null 说明已经走到了尾节点,说明不存在环
if (b == null || b.next == null) return false;
a = a.next;
b = b.next.next;
}
// a b 两个指针相遇说明存在环
return true;
}
}class Solution {
public:
bool hasCycle(ListNode *head) {
if (head == nullptr || head -> next == nullptr) return 0;
ListNode *a = head, *b = head -> next;
while (a != b) {
if (b == nullptr || b -> next == nullptr) return 0;
a = a -> next;
b = b -> next -> next;
}
return 1;
}
};142. 环形链表 II
- 哈希表
- 存储所有已经遍历过的节点地址
- 若遍历的过程中遇到已经遍历过的节点地址,说明该点就是环的起始节点
- 遍历
public class Solution {
public ListNode detectCycle(ListNode head) {
HashSet<ListNode> st = new HashSet<>();
for (ListNode i = head; i != null; i = i.next) {
if (st.contains(i)) return i;
else st.add(i);
}
return null;
}
}class Solution {
public:
ListNode *detectCycle(ListNode *head) {
set<ListNode *> st;
for (ListNode *i = head; i != nullptr; i = i -> next) {
if (st.find(i) != st.end()) return i;
else st.insert(i);
}
return nullptr;
}
};21. 合并两个有序链表
- 链表合并板子
- 同时循环遍历两个链表
- 如果两个节点都存在,比较节点值的大小,将取值小的节点加入新链表,并使其指针后移
- 否则有一方不存在,说明已经走到了链表的结尾,将剩下链表的值不断加入新链表即可
class Solution {
public ListNode mergeTwoLists(ListNode list1, ListNode list2) {
ListNode ans = new ListNode(0);
ListNode head = ans;
while (list1 != null || list2 != null) {
if (list1 != null && list2 != null) {
if (list1.val <= list2.val) {
ans.next = new ListNode(list1.val);
list1 = list1.next;
} else {
ans.next = new ListNode(list2.val);
list2 = list2.next;
}
ans = ans.next;
} else {
if (list1 != null) {
ans.next = new ListNode(list1.val);
list1 = list1.next; ans = ans.next;
}
if (list2 != null) {
ans.next = new ListNode(list2.val);
list2 = list2.next; ans = ans.next;
}
}
}
return head.next;
}
}class Solution {
public:
ListNode* mergeTwoLists(ListNode* list1, ListNode* list2) {
ListNode * head = new ListNode(0);
ListNode * ans = head;
while (list1 != nullptr || list2 != nullptr) {
if (list1 != nullptr && list2 != nullptr) {
if (list1 -> val <= list2 -> val) head -> next = new ListNode(list1 -> val), head = head -> next, list1 = list1 -> next;
else head -> next = new ListNode(list2 -> val), head = head -> next, list2 = list2 -> next;
} else {
if (list1 != nullptr) head -> next = new ListNode(list1 -> val), head = head -> next, list1 = list1 -> next;
if (list2 != nullptr) head -> next = new ListNode(list2 -> val), head = head -> next, list2 = list2 -> next;
}
}
return ans -> next;
}
};2. 两数相加
- 大整数相加模板
- 由于链表已经翻转过,因此答案也不需要再处理
- 利用 base 存储进位,同时遍历两个链表
- 如果两个节点的值都存在,则新链表的节点值为 (base + l1.val + l2.val) % 10,更新进位的值为 (base + l1.val + l2.val) / 10
- 否则说明某个链表已经遍历完毕,将剩下的进位和剩余没有加和完的链表继续遍历加和完毕即可
- 最后判断 base 是否还保留进位,如果有也要加上
class Solution {
public ListNode addTwoNumbers(ListNode l1, ListNode l2) {
int base = 0;
ListNode head = new ListNode(0);
ListNode ans = head;
while (l1 != null || l2 != null) {
if (l1 != null && l2 != null) {
int t = base + l1.val + l2.val;
head.next = new ListNode(t % 10);
head = head.next; l1 = l1.next; l2 = l2.next;
base = t / 10;
} else {
if (l1 != null) {
int t = base + l1.val;
head.next = new ListNode(t % 10);
head = head.next; l1 = l1.next;
base = t / 10;
}
if (l2 != null) {
int t = base + l2.val;
head.next = new ListNode(t % 10);
head = head.next; l2 = l2.next;
base = t / 10;
}
}
}
if (base != 0) head.next = new ListNode(base);
return ans.next;
}
}class Solution {
public:
ListNode* addTwoNumbers(ListNode* l1, ListNode* l2) {
int base = 0;
ListNode * head = new ListNode(0);
ListNode * ans = head;
while (l1 != nullptr || l2 != nullptr) {
if (l1 != nullptr && l2 != nullptr) {
int t = base + l1 -> val + l2 -> val;
head -> next = new ListNode(t % 10);
head = head -> next, l1 = l1 -> next, l2 = l2 -> next;
base = t / 10;
} else {
if (l1 != nullptr) {
int t = base + l1 -> val;
head -> next = new ListNode(t % 10);
head = head -> next, l1 = l1 -> next;
base = t / 10;
}
if (l2 != nullptr) {
int t = base + l2 -> val;
head -> next = new ListNode(t % 10);
head = head -> next, l2 = l2 -> next;
base = t / 10;
}
}
}
if (base) head -> next = new ListNode(base);
return ans -> next;
}
};19. 删除链表的倒数第 N 个结点
- 双指针
- 初始化两个指针 l 和 r
- 先让 r 后移 n 个节点,然后同时移动 l 和 r
- 当 r == null 时,此时 l 即为需要删除的节点
- 删除即将 l.next 更新为 l.next.next 即可
class Solution {
public ListNode removeNthFromEnd(ListNode head, int n) {
ListNode ans = new ListNode(0, head);
ListNode l = ans, r = ans;
for (int i = 0; i < n + 1; i ++) r = r.next;
while (r != null) {
l = l.next; r = r.next;
}
l.next = l.next.next;
return ans.next;
}
}class Solution {
public:
ListNode* removeNthFromEnd(ListNode* head, int n) {
ListNode * ans = new ListNode(0, head);
ListNode * l = ans, * r = ans;
for (int i = 0; i < n + 1; i ++) r = r -> next;
while (r != nullptr) {
l = l -> next, r = r -> next;
}
l -> next = l -> next -> next;
return ans -> next;
}
};24. 两两交换链表中的节点
- 模拟
- 利用三个指针 t,l,r
- 初始化 l 为 head,t 为 l 的前一个节点,r 为 l 的后一个节点
- 交换的顺序为:
- 使 l 指向 r 的下一个节点,即 l.next = r.next
- 使 r 指向 l,即 t 指向的节点 r.next = t.next
- 使 t 指向交换后的节点 r,即 t.next = r
- 之后需要向后移动三个指针:
- 先把 t 指向下一次需要交换的第一个节点之前,即 t = l
- 将 l 指向下一次需要交换的第一个节点,即 l = l.next
- 之后 r 指向 l 的后一个节点,r = l.next
- 注意在更新 r 的指向时,需要先判断后一个节点是否存在
class Solution {
public ListNode swapPairs(ListNode head) {
ListNode ans = new ListNode(0, head);
ListNode l = head;
if (l == null) return head;
ListNode r = head.next, t = ans;
while (r != null) {
l.next = r.next;
r.next = t.next;
t.next = r;
t = l;
l = l.next;
if (l == null) break;
else r = l.next;
}
return ans.next;
}
}class Solution {
public:
ListNode* swapPairs(ListNode* head) {
ListNode * ans = new ListNode(0, head);
ListNode * t = ans, * l = head;
if (l == nullptr) return head;
ListNode * r = l -> next;
while (r != nullptr) {
l -> next = r -> next;
r -> next = t -> next;
t -> next = r;
t = l;
l = l -> next;
if (l == nullptr) break;
r = l -> next;
}
return ans -> next;
}
};25. K 个一组翻转链表
- 模拟
- 首先判断是否存在连续的 k 长度的组
- 若存在,则对组内的 k 个节点进行翻转即可
class Solution {
public ListNode reverseKGroup(ListNode head, int k) {
ListNode ans = new ListNode(0, head);
ListNode t = ans, st = findNode(t, k);
while (t.next != null && st.next != null) {
ListNode l = t.next, r = st.next;
for (int i = 0; i < k; i++) {
ListNode temp = l.next;
l.next = r;
r = l;
l = temp;
}
ListNode temp = t.next;
t.next = r;
temp.next = l;
t = temp;
st = findNode(t, k);
}
return ans.next;
}
private ListNode findNode(ListNode head, int k) {
for (int i = 0; i < k - 1; i ++) {
if (head.next != null) head = head.next;
else break;
}
return head;
}
}class Solution {
public:
ListNode* reverseKGroup(ListNode* head, int k) {
ListNode * ans = new ListNode(0, head);
ListNode * t = ans, * st = findNode(t, k);
while (t -> next != nullptr && st -> next != nullptr) {
ListNode * l = t -> next, * r = st -> next;
for (int i = 0; i < k; i ++) {
ListNode * temp = l -> next;
l -> next = r;
r = l;
l = temp;
}
ListNode * temp = t -> next;
t -> next = r;
temp -> next = l;
t = temp;
st = findNode(t, k);
}
return ans -> next;
}
ListNode * findNode(ListNode * head, int k) {
for (int i = 0; i < k - 1; i ++) {
if (head -> next != nullptr) head = head -> next;
else break;
}
return head;
}
};138. 随机链表的复制
- 哈希表
- 题意为深拷贝一个一模一样的链表
- 由于 random 节点在拷贝时指向的节点可能还未创建
- 因此,利用哈希表存储所有新建的节点
- 遍历旧链表,对哈希表中的节点进行组装
class Solution {
public Node copyRandomList(Node head) {
HashMap<Node, Node> vis = new HashMap<>();
for (Node i = head; i != null; i = i.next) {
vis.put(i, new Node(i.val));
}
Node ans = new Node(0);
Node st = ans;
for (Node i = head; i != null; i = i.next) {
st.next = vis.get(i);
st.next.next = vis.get(i.next);
st.next.random = vis.get(i.random);
st = st.next;
}
return ans.next;
}
}class Solution {
public:
Node* copyRandomList(Node* head) {
map<Node *, Node *> vis;
for (Node * i = head; i != nullptr; i = i -> next) {
Node * node = new Node(i -> val);
vis[i] = node;
}
Node * ans = new Node(0);
Node * st = ans;
for (Node * i = head; i != nullptr; i = i -> next) {
st -> next = vis[i];
st -> next -> next = vis[i -> next];
st -> next -> random = vis[i -> random];
st = st -> next;
}
return ans -> next;
}
};148. 排序链表
- 将链表的节点值拷贝到数组中
- 对数组排序后,将节点值重新赋予即可
class Solution {
public ListNode sortList(ListNode head) {
List<Integer> num = new ArrayList<>();
for (ListNode i = head; i != null; i = i.next) {
num.add(i.val);
}
Collections.sort(num);
int idx = 0;
for (ListNode i = head; i != null; i = i.next) {
i.val = num.get(idx ++);
}
return head;
}
}class Solution {
public:
ListNode* sortList(ListNode* head) {
vector<int> num;
for (ListNode * i = head; i != nullptr; i = i -> next) {
num.push_back(i -> val);
}
sort(num.begin(), num.end());
int idx = 0;
for (ListNode * i = head; i != nullptr; i = i -> next) {
i -> val = num[idx ++];
}
return head;
}
};23. 合并 K 个升序链表
- 将链表的节点值拷贝到数组中
- 对数组排序后,将节点值重新赋予即可
class Solution {
public ListNode mergeKLists(ListNode[] lists) {
List<Integer> num = new ArrayList<>();
for (int i = 0; i < lists.length; i ++) {
for (ListNode j = lists[i]; j != null; j = j.next) {
num.add(j.val);
}
}
Collections.sort(num);
ListNode ans = new ListNode(0);
ListNode st = ans;
for (int i = 0; i < num.size(); i ++) {
st.next = new ListNode(num.get(i));
st = st.next;
}
return ans.next;
}
}class Solution {
public:
ListNode* mergeKLists(vector<ListNode*>& lists) {
vector<int> num;
for (auto p : lists) {
for (auto q = p; q != nullptr; q = q -> next) {
num.push_back(q -> val);
}
}
ListNode * ans = new ListNode(0);
ListNode * st = ans;
sort(num.begin(), num.end());
for (auto p : num) {
st -> next = new ListNode(p);
st = st -> next;
}
return ans -> next;
}
};146. LRU 缓存
-
手撕 LRU
-
首先需要理解 LRU 算法的原理:
- LRU 是一种最近不常用的缓存淘汰策略,淘汰掉最后一次使用时间最久的缓存
- 根据数据访问次数来淘汰数据的,它的核心思想是“如果数据过去被访问多次,那么将来被访问的频率也更高”
-
传统的 LRU 算法实现:
- 基于链表的结构,链表中的元素按照访问的次数从大到小排序,新插入的元素在尾部,访问后次数加一
- 当需要执行淘汰策略时,对链表进行排序,相同次数按照时间排序,删除访问次数最少的尾部元素
-
由于题目的场景很简单,因此 LRU 不需要上述传统的复杂实现,我们采用链表+哈希表的结构来解决:
- 用哈希表存储所有的链表中的节点信息,记录 key 为 int 值,value 为 链表的节点
- 用双向链表存储已缓存的节点,用于判断最近操作的对象
- get:对于 get 方法,从哈希表判断值是否存在,如果存在返回节点信息,并将在双向链表中的该节点移动到头部
- put:对于 put 方法,先从哈希表判断是否存在,如果存在则更新值,并移动到头部;否则添加到双向链表的头部和哈希表中,继续需要判断当前容量是否超出额定大小,如果超出则需要进行缓存淘汰,移除双向链表的尾部节点,并将哈希表中的该节点删除
class LRUCache { class DLinkedNode { int key; int value; DLinkedNode prev; DLinkedNode next; public DLinkedNode() {} public DLinkedNode(int key, int value) { this.key = key; this.value = value; } } private HashMapstruct DLinkedNode { int key, value; DLinkedNode * prev; DLinkedNode * next; DLinkedNode() : key(0), value(0), prev(nullptr), next(nullptr) {}; DLinkedNode(int key, int value) : key(key), value(value), prev(nullptr), next(nullptr) {}; }; class LRUCache { private: int size; int capacity; DLinkedNode * head, * tail; map
94. 二叉树的中序遍历
- 板子题
- 递归遍历左子节点和右子节点
- 中序遍历在遍历完左子节点输出
class Solution {
List<Integer> ans = new ArrayList<>();
public List<Integer> inorderTraversal(TreeNode root) {
doInorderTraversal(root);
return ans;
}
private void doInorderTraversal(TreeNode root) {
if (root == null) return ;
doInorderTraversal(root.left);
ans.add(root.val);
doInorderTraversal(root.right);
}
}class Solution {
public:
vector<int> ans;
void doInorderTraversal(TreeNode * root) {
if (root == nullptr) return ;
doInorderTraversal(root -> left);
ans.push_back(root -> val);
doInorderTraversal(root -> right);
}
vector<int> inorderTraversal(TreeNode* root) {
doInorderTraversal(root);
return ans;
}
};104. 二叉树的最大深度
- DFS
- 用 cnt 表示递归的深度
- 不断递归,每次递归 cnt + 1,表示深度 + 1
- 当遇到 TreeNode == null 时说明当前为叶子节点,更新最大的深度即可
class Solution {
int ans = 0;
public int maxDepth(TreeNode root) {
dfs (root, 0);
return ans;
}
private void dfs (TreeNode root, int cnt) {
if (root == null) {
ans = Math.max(ans, cnt);
return ;
}
dfs (root.left, cnt + 1);
dfs (root.right, cnt + 1);
}
}class Solution {
public:
int ans = 0;
void dfs(TreeNode * root, int cnt) {
if (root == nullptr) {
ans = max(ans, cnt);
return ;
}
dfs (root -> left, cnt + 1);
dfs (root -> right, cnt + 1);
}
int maxDepth(TreeNode* root) {
dfs(root, 0);
return ans;
}
};226. 翻转二叉树
- DFS
- 递归遍历,交换每个节点的左右子节点即可
class Solution {
public TreeNode invertTree(TreeNode root) {
reverseTree(root);
return root;
}
private void reverseTree(TreeNode node) {
if (node == null) return ;
else {
TreeNode t = node.left;
node.left = node.right;
node.right = t;
reverseTree(node.left);
reverseTree(node.right);
}
}
}class Solution {
public:
void reverseTree(TreeNode * root) {
if (root == nullptr) return ;
else {
TreeNode * t = root -> left;
root -> left = root -> right;
root -> right = t;
reverseTree(root -> left);
reverseTree(root -> right);
}
return ;
}
TreeNode* invertTree(TreeNode* root) {
reverseTree(root);
return root;
}
};101. 对称二叉树
- DFS
- 分别对比根节点的左右两棵子树
- 左子树的左节点和右子树的右节点对比
- 左子树的右节点和右子树的左节点对比
- 特殊情况,两个节点都不存在是对称,否则有一个不存在就不对称
class Solution {
private boolean flag = true;
public boolean isSymmetric(TreeNode root) {
dfs (root.left, root.right);
return flag;
}
private void dfs (TreeNode lnode, TreeNode rnode) {
if (lnode == null && rnode == null) return ;
if ((lnode == null && rnode != null) ||
(lnode != null && rnode == null)) {
flag = false;
return ;
}
if (lnode.val == rnode.val) {
dfs (lnode.left, rnode.right);
dfs (lnode.right, rnode.left);
} else {
flag = false;
return ;
}
}
}class Solution {
public:
bool flag = 1;
void dfs (TreeNode * lnode, TreeNode * rnode) {
if (lnode == nullptr && rnode == nullptr) return ;
if ((lnode == nullptr && rnode != nullptr) ||
(lnode != nullptr && rnode == nullptr)) {
flag = 0;
return;
}
if (lnode -> val == rnode -> val) {
dfs (lnode -> left, rnode -> right);
dfs (lnode -> right, rnode -> left);
}
else {
flag = 0;
return ;
}
}
bool isSymmetric(TreeNode* root) {
dfs (root -> left, root -> right);
return flag;
}
};543. 二叉树的直径
- DFS
- 解题思想类似二叉树的最大深度
- 这里将每个节点分别计算其左子树的深度和右子树的高度
- 那么直径即为节点左子树深度 + 右子树深度
- 在递归时,需要分别递归计算左子树和右子树深度,返回则只返回最大的子树深度即可
class Solution {
private int ans = 0;
public int diameterOfBinaryTree(TreeNode root) {
dfs (root);
return ans;
}
private int dfs (TreeNode node) {
if (node == null) return 0;
int l = dfs (node.left);
int r = dfs (node.right);
ans = Math.max(ans, l + r);
return Math.max(l, r) + 1;
}
}class Solution {
public:
int ans = 0;
int dfs (TreeNode * node) {
if (node == nullptr) return 0;
int l = dfs(node -> left);
int r = dfs(node -> right);
ans = max(ans, l + r);
return max(l, r) + 1;
}
int diameterOfBinaryTree(TreeNode* root) {
dfs (root);
return ans;
}
};102. 二叉树的层序遍历
- BFS
- 利用队列存储每一层遍历到的节点
- 用 Pair 保存节点的层次信息和节点信息
- 每次取出队头,若其层次大于等于答案长度,说明此时需要新开一层存储答案
- 每次操作队头后,将队头节点的左子节点和右子节点的层数 + 1 再次入队
- 重复上述操作,直到队列为空
class Solution {
private List<List<Integer>> ans = new ArrayList<>();
public List<List<Integer>> levelOrder(TreeNode root) {
bfs (root);
return ans;
}
private void bfs (TreeNode node) {
Queue<Pair<Integer, TreeNode>> st = new LinkedList<>();
st.offer(new Pair<>(0, node));
while (!st.isEmpty()) {
Pair<Integer, TreeNode> p = st.poll();
if (p.getValue() == null) continue;
if (p.getKey() >= ans.size()) ans.add(new ArrayList<>());
ans.get(p.getKey()).add(p.getValue().val);
if (p.getValue().left != null) st.offer(new Pair<>(p.getKey() + 1, p.getValue().left));
if (p.getValue().right != null) st.offer(new Pair<>(p.getKey() + 1, p.getValue().right));
}
}
}class Solution {
public:
vector<vector<int>> ans;
void bfs(TreeNode * node) {
queue<pair<int, TreeNode *>> st;
st.push({0, node});
while (!st.empty()) {
auto p = st.front(); st.pop();
if (p.second == nullptr) continue;
if (p.first >= ans.size()) ans.push_back(vector<int>());
ans[p.first].push_back(p.second -> val);
if (p.second -> left != nullptr) st.push({p.first + 1, p.second -> left});
if (p.second -> right != nullptr) st.push({p.first + 1, p.second -> right});
}
}
vector<vector<int>> levelOrder(TreeNode* root) {
bfs(root);
return ans;
}
};108. 将有序数组转换为二叉搜索树
- 构建二叉搜索树模板
- 每次选择区间的中间点为每一层的根节点
- 直到区间不存在可选的节点为止
class Solution {
public TreeNode sortedArrayToBST(int[] nums) {
return buildTree(nums, 0, nums.length - 1);
}
private TreeNode buildTree(int nums[], int l, int r) {
if (l > r) return null;
int mid = (l + r) >> 1;
TreeNode root = new TreeNode(nums[mid]);
root.left = buildTree(nums, l, mid - 1);
root.right = buildTree(nums, mid + 1, r);
return root;
}
}class Solution {
public:
TreeNode* sortedArrayToBST(vector<int>& nums) {
return buildTree(nums, 0, nums.size() - 1);
}
TreeNode * buildTree(vector<int> & nums, int l, int r) {
if (l > r) return nullptr;
int mid = (l + r) >> 1;
TreeNode * root = new TreeNode(nums[mid]);
root -> left = buildTree(nums, l, mid - 1);
root -> right = buildTree(nums, mid + 1, r);
return root;
}
};98. 验证二叉搜索树
- 二叉树中序遍历
- 对于一个二叉搜索树,其二叉树的中序遍历结果数值呈单调递增
- 保存二叉树中序遍历的结果,遍历结果集判断即可
class Solution {
List<Integer> st = new ArrayList<>();
public boolean isValidBST(TreeNode root) {
check(root);
for (int i = 0; i < st.size() - 1; i ++) {
if (st.get(i) >= st.get(i + 1)) return false;
}
return true;
}
private void check(TreeNode node) {
if (node == null) return ;
check(node.left);
st.add(node.val);
check(node.right);
}
}class Solution {
public:
vector<int> st;
bool isValidBST(TreeNode* root) {
check(root);
for (int i = 0; i < st.size() - 1; i ++) {
if (st[i] >= st[i + 1]) return 0;
}
return 1;
}
void check(TreeNode * node) {
if (node == nullptr) return ;
check(node -> left);
st.push_back(node -> val);
check(node -> right);
}
};230. 二叉搜索树中第K小的元素
- 二叉搜索树的性质
- 左节点的值严格小于父节点,右节点的值严格大于父节点
- 节点的左右子树亦满足上述性质
- 因此,搜索第 k 小的元素只需要按照中序遍历的结果来算,第 k 个中序遍历到的节点就是答案
class Solution {
static int ans, cnt;
public int kthSmallest(TreeNode root, int k) {
cnt = k;
dfs(root);
return ans;
}
private static void dfs(TreeNode root) {
if (root == null || cnt < 1) return ;
dfs(root.left);
if (cnt == 1) ans = root.val;
cnt --;
dfs(root.right);
}
}class Solution {
public:
int ans, cnt;
int kthSmallest(TreeNode* root, int k) {
cnt = k;
dfs (root);
return ans;
}
void dfs(TreeNode * root) {
if (root == nullptr || cnt < 1) return ;
dfs(root -> left);
if (cnt == 1) ans = root -> val;
cnt --;
dfs(root -> right);
}
};199. 二叉树的右视图
- BFS
- 对于右视图,对二叉树进行层序遍历
- 每一层从左到右遍历到的最后一个节点值即为右视图能看到的值
- 因此 BFS 层序遍历即可
class Solution {
List<Integer> ans = new ArrayList<>();
Queue<TreeNode> st = new LinkedList<>();
public List<Integer> rightSideView(TreeNode root) {
if (root == null) return ans;
st.offer(root);
while (!st.isEmpty()) {
int u = st.size();
int res = -1;
for (int i = 0; i < u; i ++) {
TreeNode p = st.poll();
res = p.val;
if (p.left != null) st.offer(p.left);
if (p.right != null) st.offer(p.right);
}
ans.add(res);
}
return ans;
}
}class Solution {
public:
vector<int> ans;
queue<TreeNode *> st;
vector<int> rightSideView(TreeNode* root) {
if (root == nullptr) return ans;
st.push(root);
while (!st.empty()) {
int u = st.size();
int res;
for (int i = 0; i < u; i ++) {
TreeNode * p = st.front(); st.pop();
res = p -> val;
if (p -> left != nullptr) st.push(p -> left);
if (p -> right != nullptr) st.push(p -> right);
}
ans.push_back(res);
}
return ans;
}
};114. 二叉树展开为链表
- 模拟
- 遍历到最右边的根节点
- 展开的过程为,同一层的节点,左节点及其子树在右节点及其子树的前面
- 即,我们需要先将右子树保存,将当前的右节点更新为其左节点,然后将右子树移动到更新过的右节点后面
- 注意,此时更新后的右子树需要移动到右子树的最后,即需要通过循环找到最后一个右子树的节点
class Solution {
public void flatten(TreeNode root) {
if (root == null) return ;
flatten(root.left);
flatten(root.right);
TreeNode r = root.right; // 保存右子树
if (root.left != null) {
root.right = root.left; // 将左子树移动到右边展开
TreeNode res = root; // 用于找到新的右子树的最后一个节点
while (res.right != null) res = res.right;
res.right = r; // 将原来的右子树插入到最后
}
root.left = null; // 最后记得将 left 置为 null
}
}class Solution {
public:
void flatten(TreeNode* root) {
if (root == nullptr) return ;
flatten (root -> left);
flatten (root -> right);
TreeNode * r = root -> right;
if (root -> left != nullptr) {
root -> right = root -> left;
TreeNode * res = root;
while (res -> right != nullptr) res = res -> right;
res -> right = r;
}
root -> left = nullptr;
}
};105. 从前序与中序遍历序列构造二叉树
- 由前序遍历的特性可知,前序遍历的第一个点即为整棵树的根节点
- 则,由根节点在中序遍历中的位置为分界线,左边为整棵树的左子树,右边为整棵树的右子树
- 即中序遍历的结果可分为
[[左子树] root [右子树]] - 由此可知,左子树和右子树遍历后的长度
- 那么前序遍历的结果可分为
[root [左子树] [右子树]] - 以构造左子树为例,前序遍历的左子树的第一个点即为左子树的根节点,对应也可以找到该点在中序遍历中的位置
- 我们以左子树的根节点在中序遍历中的位置为分界线,左边为左子树的左子树,右边为左子树的右子树
- 对于构造右子树同上
- 显然,这两个构造子树的过程是一个递归的过程
class Solution {
public TreeNode buildTree(int[] preorder, int[] inorder) {
TreeNode root = new TreeNode(preorder[0]);
build(root, preorder, inorder);
return root;
}
private TreeNode build(TreeNode root, int[] preorder, int[] inorder) {
if (root == null) return null;
int idx = findRoot(root.val, inorder);
if (idx == -1) return null;
// 构造左子树
if (idx > 0) {
// 左子树的前序遍历
int[] lp = Arrays.copyOfRange(preorder, 1, idx + 1);
// 左子树的中序遍历
int[] li = Arrays.copyOfRange(inorder, 0, idx + 1);
if (lp.length > 0) root.left = new TreeNode(lp[0]);
// 递归构造左子树的子树
build(root.left, lp, li);
}
// 构造右子树
if (idx < inorder.length - 1) {
// 右子树的前序遍历
int[] rp = Arrays.copyOfRange(preorder, idx + 1, preorder.length);
// 右子树的中序遍历
int[] ri = Arrays.copyOfRange(inorder, idx + 1, inorder.length);
if (rp.length > 0) root.right = new TreeNode(rp[0]);
// 递归构造右子树的子树
build(root.right, rp, ri);
}
return root;
}
private static int findRoot(int val, int[] inorder) {
// 找到该值在中序遍历中的下标
for (int i = 0; i < inorder.length; i ++) {
if (val == inorder[i]) return i;
}
return -1;
}
}class Solution {
public:
TreeNode* buildTree(vector<int>& preorder, vector<int>& inorder) {
TreeNode * root = new TreeNode(preorder[0]);
build(root, preorder, inorder);
return root;
}
TreeNode * build(TreeNode * root, vector<int> & preorder, vector<int> & inorder) {
if (root == nullptr) return nullptr;
int idx = findRoot(root -> val, inorder);
if (idx == -1) return nullptr;
// 构造左子树
if (idx > 0) {
vector<int> lp(preorder.begin() + 1, preorder.begin() + idx + 1);
vector<int> li(inorder.begin() ,inorder.begin() + idx);
if (lp.size() > 0) root -> left = new TreeNode(lp[0]);
build(root -> left, lp, li);
}
// 构造右子树
if (idx < preorder.size() - 1) {
vector<int> rp(preorder.begin() + idx + 1, preorder.end());
vector<int> ri(inorder.begin() + idx + 1, inorder.end());
if (rp.size() > 0) root -> right = new TreeNode(rp[0]);
build(root -> right, rp, ri);
}
return root;
}
int findRoot(int val, vector<int> & nums) {
for (int i = 0; i < nums.size(); i ++) {
if (val == nums[i]) return i;
}
return -1;
}
};124. 二叉树中的最大路径和
- DFS
- 对于当前的节点,分别计算其左右子树的最大值
- 则包含当前节点 node 的路径最大值即为 node.val + 左子树最大值 + 右子树最大值,更新答案
- 由于节点的值可能为负数,因此需要将返回的左右子树最大值和 0 取 max,如果为 0 说明不选择这个路径
class Solution {
int ans = Integer.MIN_VALUE;
public int maxPathSum(TreeNode root) {
dfs (root);
return ans;
}
int dfs (TreeNode root) {
if (root == null) return 0;
// 计算左右子树最大值,和 0 取 max
int lmax = Math.max(0, dfs (root.left));
int rmax = Math.max(0, dfs (root.right));
int cnt = root.val + lmax + rmax;
// 更新答案
ans = Math.max(ans, cnt);
// 当前节点作为路径返回时只能和一条路径取最值
return root.val + Math.max(lmax, rmax);
}
}class Solution {
public:
int ans = -0x3f3f3f3f; // 使用INT_MIN初始化
int maxPathSum(TreeNode* root) {
dfs (root);
return ans;
}
int dfs(TreeNode * root) {
if (root == nullptr) return 0;
int lmax = max(0, dfs(root -> left));
int rmax = max(0, dfs(root -> right));
int cnt = root -> val + lmax + rmax;
ans = max(ans, cnt);
return root -> val + max(lmax, rmax);
}
};200. 岛屿数量
- DFS 和 BFS 都可以做
- DFS:
- 遍历矩阵,对于每个
grid[i][j]== '1',先将grid[i][j] = '0'再进行 dfs - 利用偏移量矩阵,循环遍历四个方向,首先判断是否在边界范围内
- 其次,下一个方向
{l, r}上满足grid[l][r] == '1',则使得grid[l][r] = '0',然后递归到其方向 - 因此,直到每次递归完成,即找到了一个完整的岛屿并将其全部置为
'0',答案 ++
- 遍历矩阵,对于每个
- BFS:
- 遍历矩阵,对于每个
grid[i][j]== '1',先将grid[i][j] = '0'再进行 bfs - 先将
{i, j}作为队头入队,之后不断取队头进行如下操作: - 利用偏移量矩阵,循环遍历四个方向,首先判断是否在边界范围内
- 其次,下一个方向
{l, r}上满足grid[l][r] == '1',则使得grid[l][r] = '0',然后将{l, r}入队 - 因此,直到每次队列为空,即找到了一个完整的岛屿并将其全部置为
'0',答案 ++
- 遍历矩阵,对于每个
class Solution {
static int[] dx = {0, 1, 0, -1}, dy = {1, 0, -1, 0};
public int numIslands(char[][] grid) {
int n = grid.length, m = grid[0].length;
int ans = 0;
for (int i = 0; i < n; i ++) {
for (int j = 0; j < m; j ++) {
if (grid[i][j] == '1') {
grid[i][j] = '0';
dfs (grid, i, j, n, m);
ans ++;
}
}
}
return ans;
}
void dfs (char[][] grid, int x, int y, int n, int m) {
for (int i = 0; i < 4; i ++) {
int l = x + dx[i], r = y + dy[i];
if (l >= 0 && l < n && r >= 0 && r < m && grid[l][r] == '1') {
grid[l][r] = '0';
dfs (grid, l, r, n, m);
}
}
}
}class Solution {
public:
int dx[4] = {0, 1, 0, -1}, dy[4] = {-1, 0, 1, 0};
int numIslands(vector<vector<char>>& grid) {
int n = grid.size();
int m = grid[0].size();
int ans = 0;
for (int i = 0; i < n; i ++) {
for (int j = 0; j < m; j ++) {
if (grid[i][j] == '1') {
grid[i][j] = '0';
bfs(grid, i, j, n, m);
ans ++;
}
}
}
return ans;
}
void bfs(vector<vector<char>> & grid, int x, int y, int n, int m) {
queue<pair<int, int>> st;
st.push({x, y});
while (!st.empty()) {
auto p = st.front(); st.pop();
for (int i = 0; i < 4; i ++) {
int l = p.first + dx[i], r = p.second + dy[i];
if (l >= 0 && l < n && r >= 0 && r < m && grid[l][r] == '1') {
grid[l][r] = '0';
st.push({l, r});
}
}
}
}
};994. 腐烂的橘子
- BFS
- 循环遍历一遍,寻找腐烂过的橘子
- 将腐烂橘子所在的点全部加入队列
- 首先判断队列是否为空,如果为空则判断矩阵中是否存在未腐烂的橘子或者不存在橘子
- 当队列不为空时进行搜索,每次搜索当前 time 的点的数量即为当前队列的长度
- 利用偏移量数组进行搜索,将符合条件的位置标记为腐烂
- 当搜索完毕后,扫描一遍进行判断,是否存在未腐烂的橘子
class Solution {
static final int[] dx = {1, 0, -1, 0}, dy = {0, 1, 0, -1};
public int orangesRotting(int[][] grid) {
int n = grid.length, m = grid[0].length;
Queue<Pair<Integer, Integer>> st = new LinkedList<>();
for (int i = 0; i < n; i ++) {
for (int j = 0; j < m; j ++) {
if (grid[i][j] == 2) {
st.offer(new Pair<Integer, Integer>(i, j));
}
}
}
if (st.isEmpty()) return check(grid);
int time = 0;
while (!st.isEmpty()) {
int cnt = st.size();
for (int k = 0; k < cnt; k ++) {
Pair<Integer, Integer> p = st.poll();
for (int i = 0; i < 4; i ++) {
int l = p.getKey() + dx[i], r = p.getValue() + dy[i];
if (l >= 0 && l < n && r >= 0 && r < m && grid[l][r] == 1) {
grid[l][r] = 2;
st.offer(new Pair<Integer, Integer>(l, r));
}
}
}
time ++;
}
return check(grid) == -1 ? -1 : time - 1;
}
private int check(int[][] grid) {
for (int i = 0; i < grid.length; i ++) {
for (int j = 0; j < grid[0].length; j ++) {
if (grid[i][j] == 1) return -1;
}
}
return 0;
}
}class Solution {
public:
int dx[4] = {1, 0, -1, 0}, dy[4] = {0, 1, 0, -1};
int orangesRotting(vector<vector<int>>& grid) {
int n = grid.size(), m = grid[0].size();
queue<pair<int, int>> st;
for (int i = 0; i < n; i ++) {
for (int j = 0; j < m; j ++) {
if (grid[i][j] == 2) {
st.push({i, j});
}
}
}
if (st.empty()) return check(grid);
int time = 0;
while (!st.empty()) {
int cnt = st.size();
for (int k = 0; k < cnt; k ++) {
auto p = st.front(); st.pop();
for (int i = 0; i < 4; i ++) {
int l = p.first + dx[i], r = p.second + dy[i];
if (l >= 0 && l < n && r >= 0 && r < m && grid[l][r] == 1) {
grid[l][r] = 2;
st.push({l, r});
}
}
}
time ++;
}
return check(grid) == -1 ? -1 : time - 1;
}
int check(vector<vector<int>> & grid) {
for (auto p : grid) {
for (auto q : p) {
if (q == 1) return -1;
}
}
return 0;
}
};207. 课程表
- 拓扑排序
- 抽象一下,将每种课程视为一个节点
- 学当前课程前需要先学前置课程,即当前节点的入度不为 0
- 学完全部课程,即在该课程队列所构成的有向图中,判断该图是否满足拓扑排序
class Solution {
public boolean canFinish(int numCourses, int[][] prerequisites) {
List<Integer>[] mp = new ArrayList[numCourses]; // 邻接表
HashMap<Integer, Integer> cnt = new HashMap<>(); // 记录每个节点的入度
for (int i = 0; i < numCourses; i++) mp[i] = new ArrayList<>(); // 初始化邻接表
for (int[] p : prerequisites) {
mp[p[0]].add(p[1]); // 建图
cnt.put(p[1], cnt.getOrDefault(p[1], 0) + 1); // 被指向的点入度 ++
}
Queue<Integer> st = new LinkedList<>(); // 存储入度为 0 的点
int res = 0; // 记录走过的节点
// 将所有入度为 0 的节点入队,不断搜索,直到不存在入度为 0 的点
for (int i = 0; i < numCourses; i ++) {
if (cnt.getOrDefault(i, 0) == 0) st.offer(i);
}
while (!st.isEmpty()) {
int p = st.poll();
for (int i = 0; i < mp[p].size(); i ++) {
int t = mp[p].get(i);
cnt.put(t, cnt.get(t) - 1); // 走到的点入度 --
if (cnt.get(t) == 0) st.offer(t); // 如果当前的点入度为 0,则将该节点入队
}
res ++;
}
// 走过所有的节点,说明满足拓扑排序
return res == numCourses;
}
}class Solution {
public:
bool canFinish(int numCourses, vector<vector<int>>& prerequisites) {
vector<int> mp[numCourses];
map<int, int> cnt;
for (int i = 0; i < numCourses; i ++) cnt[i] = 0;
for (auto p : prerequisites) {
mp[p[0]].push_back(p[1]);
cnt[p[1]] ++;
}
queue<int> st;
for (int i = 0; i < numCourses; i ++) {
if (cnt[i] == 0) st.push(i);
}
int res = 0;
while (!st.empty()) {
int p = st.front(); st.pop();
for (auto q : mp[p]) {
cnt[q] --;
if (cnt[q] == 0) st.push(q);
}
res ++;
}
return res == numCourses;
}
};208. 实现 Trie (前缀树)
- Trie 板子
- Trie 原理理解即可
- 对于一颗 Trie 树,根节下连接所有单词的不同的起始首字母
- 根据起始的首字母相同的单词,不断向下扩展,如果遇到已经存在的当前字符,则转移到对应的子节点
- 如果当前字符不存在于当前节点保存的子节点起始字母,则在当前节点下新建节点存入,如此直到当前单词插入完毕
- 匹配完全插入的字符需要匹配到结束标志才能视为存在该单词
- 如果只需要匹配前缀,则不需要匹配到结束符
class Trie {
HashMap<Character, Trie> nodes; // 存储当前节点下,起始字符对应的节点
Boolean isEnd; // 结束标志
public Trie() {
this.nodes = new HashMap<>();
this.isEnd = false;
}
public void insert(String word) {
if (word.isEmpty()) { // 插完了
this.isEnd = true; // 标记此处是单词结尾
return ;
}
if (this.nodes.containsKey(word.charAt(0))) {
// 如果存在对应起始字符,说明匹配成功,从 word[1] 开始继续向下匹配或者插入
this.nodes.get(word.charAt(0)).insert(word.substring(1));
} else {
// 匹配失败,需要插入新的节点
Trie t = new Trie();
this.nodes.put(word.charAt(0), t);
t.insert(word.substring(1)); // 从 word[1] 继续插
}
}
public boolean search(String word) {
// 匹配完整单词和匹配前缀的唯一区别
if (word.isEmpty()) return this.isEnd; // 匹配结束判断是否为单词结束标志
if (this.nodes.containsKey(word.charAt(0))) {
return this.nodes.get(word.charAt(0)).search(word.substring(1));
}
return false;
}
public boolean startsWith(String prefix) {
if (prefix.isEmpty()) return true; // 匹配结束即为匹配成功
if (this.nodes.containsKey(prefix.charAt(0))) {
return this.nodes.get(prefix.charAt(0)).startsWith(prefix.substring(1));
}
return false;
}
}class Trie {
public:
map<char, Trie *> nodes;
bool isEnd;
Trie() {
this -> isEnd = 0;
}
void insert(string word) {
if (word.size() == 0) {
this -> isEnd = 1;
return ;
}
if (nodes.find(word[0]) != nodes.end()) {
nodes[word[0]] -> insert(word.substr(1));
} else {
Trie * t = new Trie();
this -> nodes[word[0]] = t;
t -> insert(word.substr(1));
}
}
bool search(string word) {
if (word.size() == 0) return this -> isEnd;
if (nodes.find(word[0]) != nodes.end()) {
return nodes[word[0]] -> search(word.substr(1));
}
return 0;
}
bool startsWith(string prefix) {
if (prefix.size() == 0) return 1;
if (nodes.find(prefix[0]) != nodes.end()) {
return nodes[prefix[0]] -> startsWith(prefix.substr(1));
}
return 0;
}
};46. 全排列
- DFS 排列板子题
- 利用全局的集合存储已经使用过的数字
- 递归遍历数组,每次将未加入过集合的数字放进预存数组 res 中
- 当 res 的大小和原数组等长,说明已经是一种排列,将其加入答案 ans 中
- 递归后返回需要恢复现场,将加入集合和 res 的数去掉
class Solution {
List<List<Integer>> ans;
Set<Integer> st;
public List<List<Integer>> permute(int[] nums) {
ans = new ArrayList<>();
st = new HashSet<>();
dfs (nums, new ArrayList<>());
return ans;
}
void dfs(int[] nums, List<Integer> res) {
if (nums.length == res.size()) {
ans.add(new ArrayList(res));
}
for (int i = 0; i < nums.length; i ++) {
if (!st.contains(nums[i])) {
st.add(nums[i]);
res.add(nums[i]);
dfs(nums, res);
st.remove(nums[i]);
res.remove(res.size() - 1);
}
}
}
}class Solution {
public:
vector<vector<int>> ans;
set<int> st;
vector<vector<int>> permute(vector<int>& nums) {
vector<int> res;
dfs(nums, res);
return ans;
}
void dfs(vector<int> & nums, vector<int> & res) {
if (nums.size() == res.size()) ans.push_back(res);
for (int i = 0; i < nums.size(); i ++) {
if (st.find(nums[i]) == st.end()) {
st.insert(nums[i]);
res.push_back(nums[i]);
dfs (nums, res);
res.pop_back();
st.erase(nums[i]);
}
}
}
};78. 子集
- DFS
- 设递归的层数为 u,则递归的总层数为从 0 到
num.length层 - 递归的每一层选择以当前遍历到的数组的下一个数字,防止递归回溯后选择重复
- 每次递归的结果加入到 res 中,当
res.size()和需要递归的总层数相等时将其加入答案 ans
class Solution {
List<List<Integer>> ans;
public List<List<Integer>> subsets(int[] nums) {
ans = new ArrayList<>();
for (int i = 0; i <= nums.length; i ++) {
dfs (0, i, nums, new ArrayList<>());
}
return ans;
}
private void dfs (int u, int k, int[] nums, List<Integer> res) {
if (res.size() == k) {
ans.add(new ArrayList<>(res));
return ;
}
for (int i = u; i < nums.length; i ++) {
res.add(nums[i]);
dfs (i + 1, k, nums, res);
res.remove(res.size() - 1);
}
}
}class Solution {
public:
vector<vector<int>> ans;
vector<vector<int>> subsets(vector<int>& nums) {
for (int i = 0; i <= nums.size(); i ++) {
vector<int> res;
dfs (0, i, nums, res);
}
return ans;
}
void dfs (int u, int k, vector<int> & nums, vector<int> & res) {
if (res.size() == k) {
ans.push_back(res);
return ;
}
for (int i = u; i < nums.size(); i ++) {
res.push_back(nums[i]);
dfs (i + 1, k, nums, res);
res.pop_back();
}
}
};17. 电话号码的字母组合
- DFS
- 与 78.子集 解法相似
- 设递归 u 层,此次递归的层数是固定的,即
digits.length()层 - 将数字对应的字符串预先存好,利用下标访问
- 每次递归,即选择
digits.charAt(u)的位置的字符串进行遍历,将备选加入 res - 回溯时需要将末尾的清除掉,当
res.length == digits.length()时加入 ans
class Solution {
static final String[] s = {"", "", "abc", "def", "ghi", "jkl", "mno", "pqrs", "tuv", "wxyz"};
List<String> ans;
public List<String> letterCombinations(String digits) {
ans = new ArrayList<>();
dfs (0, digits, new StringBuilder());
return ans;
}
private void dfs (int u, String digits, StringBuilder res) {
if (res.length() == digits.length()) {
if (res.length() != 0) ans.add(res.toString());
return ;
}
String str = s[digits.charAt(u) - '0'];
for (int i = 0; i < str.length(); i ++) {
res.append(str.charAt(i));
dfs (u + 1, digits, res);
res.delete(res.length() - 1, res.length());
}
}
}class Solution {
public:
string s[10] = {"", "", "abc", "def", "ghi", "jkl", "mno", "pqrs", "tuv", "wxyz"};
vector<string> ans;
vector<string> letterCombinations(string digits) {
string res = "";
dfs (0, digits, res);
return ans;
}
void dfs(int u, string digits, string res) {
if (res.size() == digits.size()) {
if (res.size() != 0) ans.push_back(res);
return ;
}
string str = s[digits[u] -'0'];
for (int i = 0; i < str.size(); i ++) {
res += str[i];
dfs (u + 1, digits, res);
res.pop_back();
}
}
};39. 组合总和
- DFS
- 设递归选取到第 u 层,每次选择的数字加入 cnt
- 和子集同理,只不过第 u 层的数字可以重复选取
- 当 cnt == target 将答案记录
- 剪枝,如果 cnt > target 直接 return
- 回溯,每层退出将 res 尾部添加的移除
class Solution {
List<List<Integer>> ans;
public List<List<Integer>> combinationSum(int[] candidates, int target) {
ans = new ArrayList<>();
dfs (0, 0, target, candidates, new ArrayList<>());
return ans;
}
private void dfs (int u, int cnt, int target, int[] candidates, List<Integer> res) {
if (cnt > target) return ;
if (cnt == target) {
ans.add(new ArrayList<>(res));
}
for (int i = u; i < candidates.length; i++) {
cnt += candidates[i];
res.add(candidates[i]);
dfs (i, cnt, target, candidates, res);
res.remove(res.size() - 1);
cnt -= candidates[i];
}
}
}class Solution {
public:
vector<vector<int>> ans;
vector<vector<int>> combinationSum(vector<int>& candidates, int target) {
vector<int> res;
dfs (0, 0, target, candidates, res);
return ans;
}
void dfs (int u, int cnt, int target, vector<int> & candidates, vector<int> & res) {
if (cnt > target) return ;
if (cnt == target) {
ans.push_back(res);
return ;
}
for (int i = u; i < candidates.size(); i ++) {
cnt += candidates[i];
res.push_back(candidates[i]);
dfs (i, cnt, target, candidates, res);
res.pop_back();
cnt -= candidates[i];
}
}
};22. 括号生成
- DFS
- 一共需要递归 n * 2 层进行选择
- 递归的第一层必然以
(起始,保证第一个括号合法 - 每层视为对两种括号的一次选择,用
l记录当前选择的(的数量 - 每次选择
(则l ++,选择)则l --,当l < 0时剪枝 - 当
res.length() == n * 2 && l == 0说明括号合法,记录答案
class Solution {
List<String> ans;
public List<String> generateParenthesis(int n) {
ans = new ArrayList<>();
dfs (new StringBuilder("("), n * 2, 1);
return ans;
}
private void dfs (StringBuilder res, int cnt, int l) {
if (l < 0) return ;
if (res.length() == cnt) {
if (l == 0) ans.add(new String(res.toString()));
return ;
}
res.append("(");
dfs (res, cnt, l + 1);
res.deleteCharAt(res.length() - 1);
res.append(")");
dfs (res, cnt, l - 1);
res.deleteCharAt(res.length() - 1);
}
}class Solution {
public:
vector<string> ans;
vector<string> generateParenthesis(int n) {
string res = "(";
dfs (res, n * 2, 1);
return ans;
}
void dfs (string res, int cnt, int l) {
if (l < 0) return ;
if (res.size() == cnt) {
if (l == 0) ans.push_back(res);
return ;
}
dfs (res + "(", cnt, l + 1);
dfs (res + ")", cnt, l - 1);
}
};79. 单词搜索
- DFS
- 遍历 board,搜索起始点为
board[i][j] == word.charAt(0) - 设递归的层数为 u,则递归的最大层数即为
word.length() - 递归的每一层,对当前坐标利用偏移量数组进行搜索,满足条件递归
- 利用 vis 记录走过的点,需要回溯
public class Solution {
private static final int[] dx = {1, 0, -1, 0}, dy = {0, 1, 0, -1};
public boolean exist(char[][] board, String word) {
for (int i = 0; i < board.length; i++) {
for (int j = 0; j < board[i].length; j++) {
if (board[i][j] == word.charAt(0)) {
boolean[][] vis = new boolean[board.length][board[0].length];
vis[i][j] = true;
if (dfs(board, i, j, 1, vis, word)) return true;
}
}
}
return false;
}
private boolean dfs(char[][] board, int x, int y, int u, boolean[][] vis, String word) {
if (u == word.length()) return true;
for (int i = 0; i < 4; i++) {
int l = x + dx[i], r = y + dy[i];
if (l >= 0 && l < board.length && r >= 0 && r < board[0].length && !vis[l][r] && board[l][r] == word.charAt(u)) {
vis[l][r] = true;
if (dfs(board, l, r, u + 1, vis, word)) return true;
vis[l][r] = false;
}
}
return false;
}
}class Solution {
public:
bool ans = 0;
int dx[4] = {1, 0, -1, 0}, dy[4] = {0, 1, 0, -1};
bool exist(vector<vector<char>>& board, string word) {
for (int i = 0; i < board.size(); i ++) {
for (int j = 0; j < board[i].size(); j ++) {
if (board[i][j] == word[0]) {
vector<vector<bool>> vis(board.size(), vector<bool>(board[0].size(), 0));
vis[i][j] = 1;
dfs (board, i, j, vis, 1, word);
if (ans) return 1;
}
}
}
return 0;
}
void dfs (vector<vector<char>> & board, int x, int y, vector<vector<bool>> & vis, int u, string word) {
if (u == word.size()) {
ans = 1;
return ;
}
for (int i = 0; i < 4; i ++) {
int l = x + dx[i], r = y + dy[i];
if (l >= 0 && l < board.size() && r >= 0 && r < board[0].size() && board[l][r] == word[u] && !vis[l][r]) {
vis[l][r] = 1;
dfs (board, l, r, vis, u + 1, word);
vis[l][r] = 0;
}
}
return ;
}
};131. 分割回文串
- DFS
- 设递归的层数为 u,则递归的最大层数即为
s.length() - 每次递归,即选择当前位置的字串进行构造,对 s 切分
- 将切分后的字符串 st 判断是否回文,如果是则保存至 res
- 当
u == s.length()将 res 添加至 ans 中
class Solution {
List<List<String>> ans;
public List<List<String>> partition(String s) {
ans = new ArrayList<>();
dfs (0, s, new ArrayList<>());
return ans;
}
boolean check(String s) {
for (int i = 0, j = s.length() - 1; i < j; i ++, j --) {
if (s.charAt(i) != s.charAt(j)) return false;
}
return true;
}
void dfs (int u, String s, List<String> res) {
if (u == s.length()) {
ans.add(new ArrayList<>(res));
return ;
}
for (int i = u; i < s.length(); i ++) {
String st = s.substring(u, i + 1);
if (check(st)) {
res.add(st);
dfs (i + 1, s, res);
res.remove(res.size() - 1);
}
}
}
}class Solution {
public:
vector<vector<string>> ans;
vector<vector<string>> partition(string s) {
vector<string> res;
dfs(0, s, res);
return ans;
}
bool check(string s) {
for (int i = 0, j = s.size() - 1; i < j; i ++, j --) {
if (s[i] != s[j]) return 0;
}
return 1;
}
void dfs(int u, string s, vector<string>& res) {
if (u == s.size()) {
ans.push_back(res);
return;
}
for (int i = u; i < s.size(); i ++) {
string st = s.substr(u, i - u + 1);
if (check(st)) {
res.push_back(st);
dfs(i + 1, s, res);
res.pop_back();
}
}
}
};51. N 皇后
- DFS
- 递归的每一层只做一次选择:
- 遍历 0 ~ n,选择一个位置
- 放置的条件为当前列,左对角线,右对角线均未放置过棋子
- 递归后回溯
- 难点在于快速判断对角线上是否有棋子
- 这里利用截距来标记:
- 经过某个点的斜率分别为 1 和 -1
- 即经过某个点的函数表达式分别为:y = x + k 和 y = -x + k
- 化简:k = y - x 和 k = y + x
- 当选择一个点时,即可确定坐标,继而唯一确定 k,只要 k 不相同,即不在一个直线上
class Solution {
boolean[] l = new boolean[18];
boolean[] r = new boolean[18];
// 判断当前列上是否存在棋子
boolean[] h = new boolean[18];
List<List<String>> ans;
public List<List<String>> solveNQueens(int n) {
ans = new ArrayList<>();
for (int i = 0; i < n; i ++) {
// 重置
Arrays.fill(l, false);
Arrays.fill(r, false);
Arrays.fill(h, false);
char[][] res = new char[n][n];
for (int j = 0; j < n; j ++) {
Arrays.fill(res[j], '.');
}
res[0][i] = 'Q'; h[i] = l[i] = r[- i + 9] = true;
dfs (1, n, res);
}
return ans;
}
private void dfs (int u, int n, char[][] res) {
if (u == n) {
List<String> st = new ArrayList<>();
for (int i = 0; i < n; i ++) {
st.add(new String(res[i]));
}
ans.add(st);
return ;
}
for (int i = 0; i < n; i ++) {
if (!h[i] && !l[u + i] && !r[u - i + 9]) {
res[u][i] = 'Q';
h[i] = l[u + i] = r[u - i + 9] = true;
dfs (u + 1, n, res);
h[i] = l[u + i] = r[u - i + 9] = false;
res[u][i] = '.';
}
}
}
}class Solution {
public:
// y = x + k; k = y - x + 9
// y = -x + k; k = y + x
bool l[18], r[18], h[18];
vector<vector<string>> ans;
vector<vector<string>> solveNQueens(int n) {
for (int i = 0; i < n; i ++) {
// 每次先重置
for (int j = 0; j < 18; j ++) l[j] = r[j] = h[j] = 0;
// 0, i 已经放置
h[i] = 1; l[i] = 1; r[-i + 9] = 1;
string st(n, '.'); st[i] = 'Q';
vector<string> res; res.push_back(st);
dfs (1, n, res);
}
return ans;
}
void dfs (int u, int n, vector<string> res) {
if (res.size() == n) {
ans.push_back(res);
return ;
}
for (int i = 0; i < n; i ++) {
if (!h[i] && !l[u + i] && !r[u - i + 9]) {
string st(n, '.');
st[i] = 'Q';
res.push_back(st);
h[i] = l[u + i] = r[u - i + 9] = 1;
dfs (u + 1, n, res);
h[i] = l[u + i] = r[u - i + 9] = 0;
res.pop_back();
}
}
}
};35. 搜索插入位置
- 整数二分的板子题
- 利用二分找到指定的目标值即可
- 对于我们的算法模板来说,在结束时仍没有找到目标值:
l会落在最后一次不满足target的右边,即应当插入的数的位置r会落在l - 1,也就是最后一次不满足target的位置,即应当插入的数的前一个位置
- 因此,需要插入的位置应该是
l或者r + 1
class Solution {
public int searchInsert(int[] nums, int target) {
int l = 0, r = nums.length - 1;
while (l <= r) {
int mid = (l + r) >> 1;
if (nums[mid] == target) return mid;
if (nums[mid] < target) l = mid + 1;
else r = mid - 1;
}
return l; // r + 1
}
}class Solution {
public:
int searchInsert(vector<int>& nums, int target) {
int l = 0, r = nums.size() - 1;
while (l <= r) {
int mid = (l + r) >> 1;
if (nums[mid] == target) return mid;
if (nums[mid] < target) l = mid + 1;
else r = mid -1;
}
return l; // r + 1
}
};74. 搜索二维矩阵
- 二分
- 由于二维矩阵的每一行是升序,每一列的最后的值也是升序,因此分别做二分
- 第一次二分:
- 对矩阵的每一行最后一列的值进行二分,确定是否存在某一行的区间包含
target - 由于我们模板最后一次不满足的条件是
nums[mid][nums[0].length - 1] < target - 因此最终可能包含
target的区间应为nums[l]
- 对矩阵的每一行最后一列的值进行二分,确定是否存在某一行的区间包含
- 第二次二分:
- 先判断
l是否在合法的区间内 - 之后对
nums[l]进行二分查找即可
- 先判断
class Solution {
public boolean searchMatrix(int[][] matrix, int target) {
int n = matrix.length - 1, m = matrix[0].length - 1;
// 搜索可能所在的行
int u = 0, d = n;
while (u <= d) {
int mid = (u + d) >> 1;
if (matrix[mid][m] == target) return true;
if (matrix[mid][m] < target) u = mid + 1;
else d = mid - 1;
}
if (u > n) return false;
// 搜索改行可能存在的位置
int l = 0, r = m;
while (l <= r) {
int mid = (l + r) >> 1;
if (matrix[u][mid] == target) return true;
if (matrix[u][mid] < target) l = mid + 1;
else r = mid - 1;
}
return false;
}
}class Solution {
public:
bool searchMatrix(vector<vector<int>>& matrix, int target) {
int n = matrix.size() - 1, m = matrix[0].size() - 1;
// 先搜索可能所在的行
int u = 0, d = n;
while (u <= d) {
int mid = (u + d) >> 1;
if (matrix[mid][m] == target) return 1;
if (matrix[mid][m] < target) u = mid + 1;
else d = mid - 1;
}
if (u > n) return 0;
// 搜索改行出现的位置
int l = 0, r = m;
while (l <= r) {
int mid = (l + r) >> 1;
if (matrix[u][mid] == target) return 1;
if (matrix[u][mid] < target) l = mid + 1;
else r = mid - 1;
}
return 0;
}
};34. 在排序数组中查找元素的第一个和最后一个位置
- 二分
- 数组已从小到大排序,满足单调性,由于要找到两个位置,故需要进行两次二分:
- 第一遍二分寻找第一个小于
target的数 - 第二遍二分寻找第一个大于
target的数
- 第一遍二分寻找第一个小于
- 注意要如何更新区间才能找到满足上面条件的数:
- 对于第一个位置,需要更新的区间必然在
target左边,故当nums[mid] >= target时,更新r = mid - 1 - 对于最后的位置,需要更新的区间必然在
target右边,故当nums[mid] <= target时,更新l = mid + 1
- 对于第一个位置,需要更新的区间必然在
- 显然,按照上述更新区间的方式:
- 第一种情况下,当
nums[mid] == target时,区间更新后会不断向左半部分收缩,最终找到第一个数 - 第二种情况下,当
nums[mid] == target时,区间更新后会不断向右半部分收缩,最终找到第二个数
- 第一种情况下,当
class Solution {
public int[] searchRange(int[] nums, int target) {
int n = nums.length - 1;
int[] ans = new int[2];
// 查找最小位置
int l = 0, r = n;
while (l <= r) {
int mid = (l + r) >> 1;
// 只要大于等于 target 就收缩右边界
if (nums[mid] < target) l = mid + 1;
else r = mid - 1;
}
// 找不到
if (l > n || nums[l] != target) {
ans[0] = ans[1] = -1;
return ans;
} else ans[0] = l;
// 查找最大位置
// 重置
l = 0; r = n;
while (l <= r) {
int mid = (l + r) >> 1;
// 只要小于等于 target 就收缩左边界
if (nums[mid] <= target) l = mid + 1;
else r = mid - 1;
}
ans[1] = l - 1; // l 会落在最后一次不满足条件的位置的右边
return ans;
}
}class Solution {
public:
vector<int> searchRange(vector<int>& nums, int target) {
int n = nums.size() - 1;
vector<int> ans(2);
// 第一次二分找最小位置
int l = 0, r = n;
while (l <= r) {
int mid = (l + r) >> 1;
if (nums[mid] < target) l = mid + 1;
else r = mid - 1;
}
if (l > n || nums[l] != target) {
// 没找到
ans[0] = ans[1] = -1;
return ans;
} else ans[0] = l;
// 重置
l = 0, r = n;
while (l <= r) {
int mid = (l + r) >> 1;
if (nums[mid] <= target) l = mid + 1;
else r = mid - 1;
}
ans[1] = l - 1; // l 会落在第一个不满 条件的数的右边
return ans;
}
};153. 寻找旋转排序数组中的最小值
- 二分
- 原先的数组是从小到大有序的
- 旋转后会以某个旋转点开始将数组分为部分,这两部分分别按照从小到大排列
- 因此,二分找到旋转点即为数组的最小值
class Solution {
public int findMin(int[] nums) {
int t = nums[0];
int l = 0, r = nums.length - 1;
while (l <= r) {
int mid = (l + r) >> 1;
if (nums[mid] >= t) l = mid + 1;
else r = mid - 1;
}
if (l > nums.length - 1) return t;
return nums[l];
}
}class Solution {
public:
int findMin(vector<int>& nums) {
// 找到旋转点即可
int t = nums[0];
int l = 0, r = nums.size() - 1;
while (l <= r) {
int mid = (l + r) >> 1;
if (nums[mid] >= t) l = mid + 1;
else r = mid - 1;
}
if (l > nums.size() - 1) return t;
return nums[l];
}
};4. 寻找两个正序数组的中位数
- 二分好难,不会不会 🤡
- 合并数组找中位数得了
class Solution {
public double findMedianSortedArrays(int[] nums1, int[] nums2) {
int n = nums1.length + nums2.length;
int[] nums = new int[n];
int idx1 = 0, idx2 = 0, idx = 0;
while (idx1 < nums1.length && idx2 < nums2.length) {
if (nums1[idx1] < nums2[idx2]) nums[idx ++] = nums1[idx1 ++];
else nums[idx ++] = nums2[idx2 ++];
}
while (idx1 < nums1.length) nums[idx ++] = nums1[idx1 ++];
while (idx2 < nums2.length) nums[idx ++] = nums2[idx2 ++];
if ((n & 1) == 1) return nums[n >> 1];
else return ((double) nums[n >> 1] + nums[(n - 1) >> 1]) / 2;
}
}class Solution {
public:
double findMedianSortedArrays(vector<int>& nums1, vector<int>& nums2) {
vector<int> nums;
int idx1 = 0, idx2 = 0;
while (idx1 < nums1.size() && idx2 < nums2.size()) {
if (nums1[idx1] < nums2[idx2]) nums.push_back(nums1[idx1 ++]);
else nums.push_back(nums2[idx2 ++]);
}
while (idx1 < nums1.size()) nums.push_back(nums1[idx1 ++]);
while (idx2 < nums2.size()) nums.push_back(nums2[idx2 ++]);
int n = nums.size();
if (n & 1 == 1) return nums[n >> 1];
else return ((double) nums[n >> 1] + nums[(n - 1) >> 1]) / 2;
}
};20. 有效的括号
- 栈
- 遍历字符串
s将(、{、[入栈 - 如果遇到
)、}、]则判断栈顶是否为其相反的符号- 如果是,则将栈顶出栈,继续扫描匹配
- 否则不匹配,直接返回
false
- 扫描完后判断栈是否为空,如果为空说明全部匹配完毕
class Solution {
public boolean isValid(String s) {
Stack<Character> st = new Stack<>();
for (int i = 0; i < s.length(); i++) {
char op = s.charAt(i);
if (op == '(' || op == '{' || op == '[') {
st.push(op);
} else {
if (st.isEmpty()) {
return false;
}
if ((op == ')' && st.peek() == '(')
|| (op == '}' && st.peek() == '{')
|| (op == ']' && st.peek() == '[')) {
st.pop();
} else {
return false;
}
}
}
return st.isEmpty();
}
}class Solution {
public:
bool isValid(string s) {
stack<char> st;
for (int i = 0; i < s.size(); i ++) {
if (s[i] == '(' || s[i] == '{' || s[i] == '[') st.push(s[i]);
else {
if (st.empty()) return 0;
if (s[i] == ')' && st.top() == '(') st.pop();
else if (s[i] == '}' && st.top() == '{') st.pop();
else if (s[i] == ']' && st.top() == '[') st.pop();
else return 0;
}
}
return st.empty();
}
};155. 最小栈
- 双栈
- 用 st 存储当前值栈,用 ans 存储最小值栈
- 每次 st 入栈,将 ans 栈顶和 st 入栈值取最小入 ans
- 每次 st 出栈,同时出 st 和 ans
- 返回最小值即为 ans 栈顶
class MinStack {
Stack<Integer> st;
Stack<Integer> ans;
public MinStack() {
st = new Stack<>();
ans = new Stack<>();
// 这里初始化一个最大值用于和第一个入栈的值作比较
ans.push(Integer.MAX_VALUE);
}
public void push(int val) {
st.push(val);
ans.push(Math.min(ans.peek(), val));
}
public void pop() {
st.pop();
ans.pop();
}
public int top() {
return st.peek();
}
public int getMin() {
return ans.peek();
}
}class MinStack {
public:
stack<int> ans;
stack<int> st;
MinStack() {
ans.push(INT_MAX);
}
void push(int val) {
st.push(val);
ans.push(min(ans.top(), val));
}
void pop() {
st.pop();
ans.pop();
}
int top() {
return st.top();
}
int getMin() {
return ans.top();
}
};394. 字符串解码
- 双栈
- 用 word 存储当前已经解码的字符串,nums 存储解码字符串所需要的数字数量
- 遍历 s,用 num 暂存数字,ans 暂存当前拼接的字符串
- 若遇到小写字母,将其拼接在 ans 后
- 若遇到数字字符,将其累计到 num
- 若遇到
[,则将 num 数字压入 nums 中,将 ans 压入 word,然后重置 num 和 ans - 若遇到
],则将 word 栈顶出栈记为 st,nums 栈顶出栈记为 t,将 ans 重复 t 次拼接到 st,然后更新 ans 为 st
- 遍历结束后,ans 即为答案
class Solution {
public String decodeString(String s) {
Stack<String> word = new Stack<>();
Stack<Integer> nums = new Stack<>();
int num = 0;
StringBuilder ans = new StringBuilder();
for (int i = 0; i < s.length(); i ++) {
char c = s.charAt(i);
if (c >= '0' && c <= '9') {
num = num * 10 + (c - '0');
} else if (c == '[') {
nums.push(num);
word.push(ans.toString());
num = 0; ans = new StringBuilder();
} else if (c >= 'a' && c <= 'z') {
ans.append(c);
} else if (c == ']') {
int t = nums.pop(); String k = word.pop();
StringBuilder st = new StringBuilder(k);
st.append(ans.toString().repeat(t));
ans = st;
}
}
return ans.toString();
}
}class Solution {
public:
string decodeString(string s) {
stack<string> word;
stack<int> nums;
string ans = "";
int num = 0;
for (int i = 0; i < s.size(); i++) {
if (isdigit(s[i])) {
num = num * 10 + (s[i] - '0');
} else if (s[i] == '[') {
nums.push(num);
word.push(ans);
num = 0; ans = "";
} else if (isalpha(s[i])) {
ans += s[i];
} else if (s[i] == ']') {
int cnt = nums.top(); nums.pop();
string st = word.top(); word.pop();
for (int j = 0; j < cnt; j ++) {
st += ans;
}
ans = st;
}
}
return ans;
}
};739. 每日温度
- 单调栈
- 令栈 st 存储当前日的下标
- 遍历
temperatures- 若
temperatures[i]小于栈顶下标对应的温度:说明比栈顶温度高的日期在后面,将i压入 st - 反之:说明
temperatures[i]温度高,用 while 循环不断取栈顶比较,然后更新栈顶下标到i的距离即为答案天数
- 若
class Solution {
public int[] dailyTemperatures(int[] temperatures) {
Stack<Integer> st = new Stack<>();
int[] ans = new int[temperatures.length];
for (int i = 0; i < temperatures.length; i ++) {
while (!st.isEmpty() && temperatures[i] > temperatures[st.peek()]) {
int idx = st.pop();
ans[idx] = i - idx;
}
st.push(i);
}
return ans;
}
}class Solution {
public:
vector<int> dailyTemperatures(vector<int>& temperatures) {
stack<int> st;
vector<int> ans(temperatures.size(), 0);
for (int i = 0; i < temperatures.size(); i++) {
while (!st.empty() && temperatures[i] > temperatures[st.top()]) {
int idx = st.top(); st.pop();
ans[idx] = i - idx;
}
st.push(i);
}
return ans;
}
};84. 柱状图中最大的矩形
- 单调栈
- 枚举 heights[i],可以形成的最大矩形为从该位置向左右两侧扩展,直到遇到比 heights[i] 低的柱子为止
- 因此,对于 heights[i],需要快速找到其左边第一个比他低的和右侧第一个比他低的柱子的未知
- 利用单调栈:
- 栈为空直接压入当前位置下标
- 若栈顶下标对应高度高度大于 heights[i],则需要不断出栈,直到栈内元素对应的高度单调递增
- 之后分别更新左侧和右侧最近的低于该高度的下标为栈顶元素即可
- 遍历 heights,对于每一个柱子求左右两侧低于其高度柱子之间的距离 * 该柱子高度取最大值即为答案
class Solution {
public int largestRectangleArea(int[] heights) {
Stack<Integer> stl = new Stack<>();
Stack<Integer> str = new Stack<>();
int[] l = new int[heights.length];
int[] r = new int[heights.length];
for (int i = 0; i < heights.length; i ++) {
while (!stl.isEmpty() && heights[stl.peek()] >= heights[i]) {
stl.pop();
}
l[i] = stl.isEmpty() ? -1 : stl.peek();
stl.push(i);
}
for (int i = heights.length - 1; i >= 0; i --) {
while (!str.isEmpty() && heights[str.peek()] >= heights[i]) {
str.pop();
}
r[i] = str.isEmpty() ? heights.length : str.peek();
str.push(i);
}
int ans = 0;
for (int i = 0; i < heights.length; i ++) {
ans = Math.max(ans, heights[i] * (r[i] - l[i] - 1));
}
return ans;
}
}class Solution {
public:
int largestRectangleArea(vector<int>& heights) {
stack<int> stl, str;
const int N = 1e5 + 10;
int l[N] = {0}, r[N] = {0};
for (int i = 0; i < heights.size(); i++) {
while (!stl.empty() && heights[stl.top()] >= heights[i]) stl.pop();
l[i] = stl.empty() ? -1 : stl.top();
stl.push(i);
}
for (int i = heights.size() - 1; i >= 0; i--) {
while (!str.empty() && heights[str.top()] >= heights[i]) str.pop();
r[i] = str.empty() ? heights.size() : str.top();
str.push(i);
}
int ans = 0;
for (int i = 0; i < heights.size(); i++) {
ans = max(ans, heights[i] * (r[i] - l[i] - 1));
}
return ans;
}
};215. 数组中的第K个最大元素
- 桶排序
- 用 vis 标记 nums[i],即 vis[nums[i]] 的值的数量
- 注意这里 nums[i] 可能为负数,因此需要一个偏移量保证数组下标合法
class Solution {
public int findKthLargest(int[] nums, int k) {
int T = (int)1e4 + 1, N = 2 * T;
int[] vis = new int[N];
for (int i = 0; i < nums.length; i ++) {
vis[nums[i] + T] ++;
}
int cnt = 0;
for (int i = N - 1; i >= 0; i --) {
cnt += vis[i];
if (cnt >= k) return i - T;
}
return -1;
}
}class Solution {
public:
int findKthLargest(vector<int>& nums, int k) {
const int T = 1e4 + 1, N = 2 * T;
int vis[N] = {0};
for (auto p : nums) {
vis[p + T] ++;
}
int cnt = 0;
for (int i = N - 1; i >= 0; i --) {
cnt += vis[i];
if (cnt >= k) return i - T;
}
return -1;
}
};347. 前 K 个高频元素
- 优先队列
- 按照元素出现的数量进行优先级排序即可
class Solution {
public int[] topKFrequent(int[] nums, int k) {
Map<Integer, Integer> vis = new HashMap<>();
PriorityQueue<Map.Entry<Integer, Integer>> st = new PriorityQueue<>(
(a, b) -> b.getValue() - a.getValue()
);
int[] ans = new int[k];
for (int p : nums) {
vis.put(p, vis.getOrDefault(p, 0) + 1);
}
for (Map.Entry<Integer, Integer> entry : vis.entrySet()) {
st.add(entry);
}
for (int i = 0; i < k; i ++) {
ans[i] = st.poll().getKey();
}
return ans;
}
}class Solution {
public:
vector<int> topKFrequent(vector<int>& nums, int k) {
map<int, int> vis;
priority_queue<pair<int, int>> st;
vector<int> ans;
for(int p : nums) {
vis[p] ++;
}
for (pair<int, int> p : vis) {
st.push({p.second, p.first});
}
while(k --) {
ans.push_back(st.top().second);
st.pop();
}
return ans;
}
};295. 数据流的中位数
- 优先队列
- 用两个优先队列:
- 一个存储较大的部分 maxn
- 一个存储较小的部分 minn
- 新增值的时候判断和 maxn 比较,如果小于则加入,否则加入 minn
- 之后判断两个队列大小,进行平衡,即将长度长的队首取出加到长度短的队列中
- 注意队列大小,我们需要允许 maxn 大于 minn 一个单位,便于取中位数判断
- 取中间值先判断 maxn 的大小是否大于 minn
- 如果是说明总数量为奇数,直接返回 maxn 的队首即可
- 反之,返回 maxn 和 minn 队首取平均值
class MedianFinder {
PriorityQueue<Integer> maxn, minn;
public MedianFinder() {
maxn = new PriorityQueue<>((a, b) -> b - a);
minn = new PriorityQueue<>();
}
public void addNum(int num) {
if (maxn.isEmpty() || num <= maxn.peek()) {
maxn.add(num);
} else {
minn.add(num);
}
if (maxn.size() > minn.size() + 1) {
minn.add(maxn.poll());
} else if (minn.size() > maxn.size()) {
maxn.add(minn.poll());
}
}
public double findMedian() {
return maxn.size() > minn.size() ? maxn.peek() : (minn.peek() + maxn.peek()) / 2.0;
}
}class MedianFinder {
public:
priority_queue<int> maxn;
priority_queue<int, vector<int>, greater<int>> minn;
MedianFinder() {
}
void addNum(int num) {
if (maxn.empty() || num <= maxn.top()) {
maxn.push(num);
} else {
minn.push(num);
}
if (maxn.size() > minn.size() + 1) {
minn.push(maxn.top());
maxn.pop();
} else if (minn.size() > maxn.size()) {
maxn.push(minn.top());
minn.pop();
}
}
double findMedian() {
if (maxn.size() > minn.size()) {
return maxn.top();
} else {
return (maxn.top() + minn.top()) / 2.0;
}
}
};121. 买卖股票的最佳时机
- 贪心
- 用 minn 记录最低的股票价格
- 遍历 prices,更新 minn 为最低价格,计算利润为 prices[i] - minn
class Solution {
public int maxProfit(int[] prices) {
int ans = 0, minn = prices[0];
for (int i = 0; i < prices.length; i ++) {
minn = Math.min(minn, prices[i]);
ans = Math.max(ans, prices[i] - minn);
}
return ans;
}
}class Solution {
public:
int maxProfit(vector<int>& prices) {
int minn = prices[0];
int ans = 0;
for (int p : prices) {
minn = min(minn, p);
ans = max(ans, p - minn);
}
return ans;
}
};55. 跳跃游戏
- 贪心
- 设当前所在的位置为 idx
- 则从当前位置开始,可以走到的点为 idx + nums[idx]
- 那么我们需要判断在 idx + 1 ~ idx + nums[idx] 之间的点 i,可以走到后面的最远距离,即 i + nums[i]
- 因此每次只需要将 idx 跳跃到使得 i + nums[i] 值最大的位置即可
class Solution {
public boolean canJump(int[] nums) {
int idx = 0;
while (idx < nums.length) {
if (idx >= nums.length - 1 || idx + nums[idx] >= nums.length - 1) return true;
if (nums[idx] == 0) return false;
int cnt = 0, res = idx;
for (int i = idx + 1; i <= idx + nums[idx] && i < nums.length; i ++) {
if (i + nums[i] >= cnt) {
cnt = i + nums[i];
res = i;
}
}
idx = res;
}
return false;
}
}class Solution {
public:
bool canJump(vector<int>& nums) {
int idx = 0;
while (idx < nums.size()) {
if (idx >= nums.size() - 1 || idx + nums[idx] >= nums.size() - 1) return 1;
if (nums[idx] == 0) return 0;
int cnt = 0, res = idx;
for (int i = idx + 1; i <= idx + nums[idx] && i < nums.size(); i ++) {
if (i + nums[i] >= cnt) {
cnt = i + nums[i];
res = i;
}
}
idx = res;
}
return 0;
}
};45. 跳跃游戏 II
- 贪心
- 设当前所在的位置为 idx
- 则从当前位置开始,可以走到的点为 idx + nums[idx]
- 那么我们需要判断在 idx + 1 ~ idx + nums[idx] 之间的点 i,可以走到后面的最远距离,即 i + nums[i]
- 因此每次只需要将 idx 跳跃到使得 i + nums[i] 值最大的位置
- 每次循环记录一次跳跃次数即可
class Solution {
public int jump(int[] nums) {
int idx = 0, ans = 0;
while (idx < nums.length) {
if (idx >= nums.length - 1) return ans;
if (idx + nums[idx] >= nums.length - 1) return ans + 1;
int cnt = 0, res = idx;
for (int i = idx + 1; i <= idx + nums[idx]; i ++) {
if (i + nums[i] >= cnt) {
cnt = i + nums[i];
res = i;
}
}
idx = res; ans ++;
}
return ans;
}
}class Solution {
public:
int jump(vector<int>& nums) {
int idx = 0, ans = 0;
while (idx < nums.size()) {
if (idx >= nums.size() - 1) return ans;
if (idx + nums[idx] >= nums.size() - 1) return ans + 1;
int cnt = 0, res = 0;
for (int i = idx + 1; i <= idx + nums[idx] && i < nums.size(); i ++) {
if (i + nums[i] >= cnt) {
cnt = i + nums[i];
res = i;
}
}
idx = res; ans ++;
}
return ans;
}
};763. 划分字母区间
- 贪心
- 根据一个可以被划分的区间,易知:
- 区间内所有字符在后续的区间不出现
- 即推出,对于区间内所有的字符,最后一次出现的位置一定在该区间内部
- 因此,我们需要遍历 s,用 vis 记录所有字符最后一次出现的下标
- 再次遍历 s,对于 s[i]:
- 其划分的区间最小为当前字符第一次出现的位置到最后一次出现的位置,即区间范围为 i ~ vis[s[i]]
- 那么根据我们上述的推论,这个区间内所有的字符也应该满足推论的条件
- 故对于 i ~ vis[s[i]] 这个区间内的字符:
- 对于 i ~ vis[s[i]] 区间的 j,需要满足 j ~ vis[s[j]]
- 因此 s[i] 最终的区间范围应该是 i ~ max(vis[s[i]], vis[s[j]])
- 根据之前的推论,我们需要需要重复上述步骤不断更新 s[i] 最终划分的区间
- 最后将 s[i] 划分的结果存入 ans,继续按照上述模式进行划分,直到所有区间划分完毕即可
class Solution {
public List<Integer> partitionLabels(String s) {
List<Integer> ans = new ArrayList<>();
HashMap<Character, Integer> vis = new HashMap<>();
for (int i = 0; i < s.length(); i ++) {
vis.put(s.charAt(i), i);
}
for (int i = 0; i < s.length(); i ++) {
int idx = vis.get(s.charAt(i));
for (int j = i + 1; j < idx; j ++) {
if (vis.get(s.charAt(j)) > idx) { // 不断更新最大区间
idx = vis.get(s.charAt(j));
}
}
ans.add(idx - i + 1);
i = idx;
}
return ans;
}
}class Solution {
public:
vector<int> partitionLabels(string s) {
vector<int> ans;
map<char, int> vis;
for (int i = 0; i < s.size(); i ++) {
vis[s[i]] = i;
}
for (int i = 0; i < s.size(); i ++) {
int idx = vis[s[i]];
for (int j = i + 1; j < idx; j ++) {
if (vis[s[j]] > idx) idx = vis[s[j]];
}
ans.push_back(idx - i + 1);
i = idx;
}
return ans;
}
};70. 爬楼梯
- dp
- 设 dp[i] 表示到达第 i 层的方案数量
- 则由题意可知,到达第 i 层的方案数量为第 i - 1 层和第 i - 2 层方案数量之和
- 即,dp[i] = dp[i - 1] + dp[i - 2]
- 初始化:dp[0] = dp[1] = 1
class Solution {
public int climbStairs(int n) {
int[] dp = new int[n + 1];
dp[0] = dp[1] = 1;
for (int i = 2; i <= n; i ++) {
dp[i] = dp[i - 1] + dp[i - 2];
}
return dp[n];
}
}class Solution {
public:
int climbStairs(int n) {
int dp[50] = {0};
dp[0] = dp[1] = 1;
for (int i = 2; i <= n; i ++) {
dp[i] = dp[i - 1] + dp[i - 2];
}
return dp[n];
}
};118. 杨辉三角
- 模拟
- 由定义可知:
- 第 n 层一共有 n 个数,且首位值均为 1
- 对于第 n - 1 层,两两相加的值为第 n 层首位中间的值
- 即,用 ans 保存每一层的值,模拟计算下一层即可
class Solution {
public List<List<Integer>> generate(int numRows) {
List<Integer> res = new ArrayList<>();
res.add(1);
List<List<Integer>> ans = new ArrayList<>();
ans.add(res);
for (int i = 2; i <= numRows; i ++) {
List<Integer> cnt = new ArrayList<>();
cnt.add(1);
res = ans.get(i - 2);
for (int j = 1; j < res.size(); j ++) {
cnt.add(res.get(j) + res.get(j - 1));
}
cnt.add(1);
ans.add(cnt);
}
return ans;
}
}class Solution {
public:
vector<vector<int>> generate(int numRows) {
vector<int> res(1, 1);
vector<vector<int>> ans;
ans.push_back(res);
for (int i = 2; i <= numRows; i ++) {
vector<int> cnt(i, 1);
res = ans[i - 2];
int idx = 1;
for (int j = 1; j < res.size(); j ++) {
cnt[idx ++] = res[j] + res[j - 1];
}
ans.push_back(cnt);
}
return ans;
}
};198. 打家劫舍
- dp
- 设 dp 数组,dp[i] 表示打劫前 i 家能获得的最多的金额
- 遍历 nums,对于第 i 家:
- 打劫:由于打劫第 i 家必然不能打劫第 i - 1 家,则 dp[i] = nums[i - 2] + nums[i]
- 不打劫:则当前金额不变,即 dp[i] = dp[i - 1]
- 最终打劫第 i 家获得的最多金额为上述两种情况取最大值
- 故 dp[i] = max(dp[i - 2] + nums[i], dp[i - 1])
- 初始化,dp[0] = nums[0],对于第 1 家为 dp[1] = max(nums[0], nums[1])
class Solution {
public int rob(int[] nums) {
if (nums.length == 1) return nums[0];
int[] dp = new int[nums.length];
dp[0] = nums[0]; dp[1] = Math.max(nums[0], nums[1]);
for (int i = 2; i < nums.length; i ++) {
dp[i] = Math.max(dp[i - 2] + nums[i], dp[i - 1]);
}
return dp[nums.length - 1];
}
}class Solution {
public:
int rob(vector<int>& nums) {
if (nums.size() == 1) return nums[0];
int dp[103] = {0};
dp[0] = nums[0]; dp[1] = max(nums[0], nums[1]);
for (int i = 2; i < nums.size(); i ++) {
dp[i] = max(dp[i - 2] + nums[i], dp[i - 1]);
}
return dp[nums.size() - 1];
}
};279. 完全平方数
- DFS + 贪心
- 设 u 为当前需要凑为完全平方的数,cnt 为总数量
- 递归的每一层,从最大的平方根开始搜索,即 sqrt(u) ~ 1
- 若 u == 0 说明搜索完毕,更新 cnt 总数量的最小值
class Solution {
public:
int ans = INT_MAX;
void dfs (int u, int cnt) {
if (cnt >= ans) return ;
if (u == 0) {
ans = min(ans, cnt);
}
for (int i = sqrt(u); i >= 1; i --) {
dfs (u - i * i, cnt + 1);
}
}
int numSquares(int n) {
dfs (n, 0);
return ans;
}
};class Solution {
int ans = Integer.MAX_VALUE;
void dfs (int u, int cnt) {
if (cnt >= ans) {
return ;
}
if (u == 0) {
ans = Math.min(ans, cnt);
return ;
}
for (int i = (int)Math.sqrt(u); i >= 0; i --) {
dfs (u - i * i, cnt + 1);
}
}
public int numSquares(int n) {
dfs (n, 0);
return ans;
}
}322. 零钱兑换
- dp
- 设 dp 数组,对于 dp[i] 表示凑到 i 元的所需硬币最小数量
- 初始化 dp[i] 为一个极大的值,dp[0] = 0
- 枚举 amount,同时枚举的每个 i 金额遍历 coins
- 当金额 i 大于 coins[j] 时,说明可以选 coins
- 需要更新为 dp[i - coins[j]] + 1
- 由于对于金额 i ,遍历的 coins 不只一种选择,因此需要在 dp[i] 和 dp[i - coins[j]] + 1 取最小
class Solution {
public int coinChange(int[] coins, int amount) {
final int N = (int)1e4 + 3;
int[] dp = new int[amount + 1];
for (int i = 0; i < dp.length; i ++) dp[i] = N;
dp[0] = 0;
for (int i = 1; i <= amount; i ++) {
for (int j = 0; j < coins.length; j ++) {
if (i - coins[j] >= 0) {
dp[i] = Math.min(dp[i], dp[i - coins[j]] + 1);
}
}
}
return (dp[amount] == N) ? -1 : dp[amount];
}
}class Solution {
public:
int coinChange(vector<int>& coins, int amount) {
const int N = 1e4 + 3;
int dp[N];
for (int i = 0; i <= amount; i ++) dp[i] = N;
dp[0] = 0;
for (int i = 1; i <= amount; i ++) {
for (int j = 0; j < coins.size(); j ++) {
if (i - coins[j] >= 0) {
dp[i] = min(dp[i], dp[i - coins[j]] + 1);
}
}
}
return dp[amount] == N ? -1 : dp[amount];
}
};139. 单词拆分
- dp
- 设 dp 数组,dp[i] 表示字符串 s 从 0 开始到 i 的字串是否可以通过字典凑出
- 枚举 i,即枚举 s 的字串长度从 0 到 s.length(),对于第 i 个字串:
- 遍历 wordDict,计 wordDict[i] 长度为 t
- 若 i - t >= 0 说明 wordDict[i] 可以和之前的 i - t 长度的字串拼接
- 因此,如果 dp[i - t] 可以凑出且 wordDict[i] 和 s 拼接后的该字串相等,说明可以凑出
- 由于遍历 wordDict 情况有多种,因此所有方案中只要有一个即视为成功,即 dp[i] = max(dp[i], dp[i - t])
- 初始化 dp[0] = 1,因为长度为 0 的字串是一定合法的
class Solution {
public boolean wordBreak(String s, List<String> wordDict) {
int[] dp = new int[s.length() + 1];
dp[0] = 1;
for (int i = 1; i <= s.length(); i ++) {
for (String string : wordDict) {
int t = string.length();
if (i - t >= 0 && s.substring(i - t, i).equals(string)) {
dp[i] = Math.max(dp[i], dp[i - t]);
}
}
}
return dp[s.length()] == 1;
}
}class Solution {
public:
bool wordBreak(string s, vector<string>& wordDict) {
const int N = 301;
bool dp[N] = {0};
dp[0] = 1;
for (int i = 1; i <= s.size(); i ++) {
for (int j = 0; j < wordDict.size(); j ++) {
int t = wordDict[j].size();
if (t <= i && s.substr(i - t, t) == wordDict[j]) {
dp[i] = max(dp[i], dp[i - t]);
}
}
}
return dp[s.size()];
}
};300. 最长递增子序列
- dp
- 设 dp[i] 表示以 nums[i] 结尾的最长递增子序列的长度
- 对于每个 i :
- 利用 j 遍历 i 之前的数,进一步判断是否可以构成严格单调递增子序列
- 即,当 i > j 且 nums[i] > nums[j] 时,dp[i] = max(dp[i], dp[j] + 1)
- 每次枚举 i 都需要更新当前最长子序列的长度
- 初始化,dp [i] = 1
class Solution {
public int lengthOfLIS(int[] nums) {
int[] dp = new int[nums.length + 1];
int ans = 1;
for (int i = 0; i < dp.length; i ++) dp[i] = 1;
for (int i = 1; i < nums.length; i ++) {
for (int j = 0; j < i; j ++) {
if (nums[i] > nums[j]) {
dp[i] = Math.max(dp[i], dp[j] + 1);
}
}
ans = Math.max(ans, dp[i]);
}
return ans;
}
}class Solution {
public:
int lengthOfLIS(vector<int>& nums) {
const int N = 25001;
int dp[N] = {1};
int ans = 1;
for (int i = 0; i < nums.size(); i ++) dp[i] = 1;
for (int i = 1; i < nums.size(); i ++) {
for (int j = 0; j < i; j ++) {
if (nums[i] > nums[j]) {
dp[i] = max(dp[i], dp[j] + 1);
}
}
ans = max(ans, dp[i]);
}
return ans;
}
};152. 乘积最大子数组
- dp
- 设 dp 数组,dp[i] 表示以 nums[i] 结尾的连续的子数组最大乘积
- 遍历 nums[i],对于第 i 个数
- 如果选 nums[i],则乘积为 dp[i - 1] * nums[i]
- 如果不选,则乘积为其本身,即 nums[i]
- 由于题目所给的 nums[i] 不一定都为正数,存在负数的可能
- 因此我们需要两个 dp 数组来存:
- dp1:表示以 nums[i] 结尾的连续的子数组最大乘积
- dp2:表示以 nums[i] 结尾的连续的子数组最小乘积
- 故,我们需要对 nums[i]、dp1[i - 1] nums[i]、dp2[i - 1] nums[i] 取最大值即为答案
- 同时需要更新 dp1 和 dp2
- 初始化 dp1[0] = dp2[0] = nums[0]
class Solution {
public int maxProduct(int[] nums) {
int[] dp1 = new int[nums.length + 1];
int[] dp2 = new int[nums.length + 1];
dp1[0] = dp2[0] = nums[0];
int ans = nums[0];
for (int i = 1; i < nums.length; i ++) {
dp1[i] = Math.max(nums[i], Math.max(dp1[i - 1] * nums[i], dp2[i - 1] * nums[i]));
dp2[i] = Math.min(nums[i], Math.min(dp1[i - 1] * nums[i], dp2[i - 1] * nums[i]));
ans = Math.max(ans, dp1[i]);
}
return ans;
}
}class Solution {
public:
int maxProduct(vector<int>& nums) {
const int N = nums.size() + 1;
int dp1[N], dp2[N];
dp1[0] = dp2[0] = nums[0];
int ans = nums[0];
for (int i = 1; i < nums.size(); i ++) {
dp1[i] = max(nums[i], max(dp1[i - 1] * nums[i], dp2[i - 1] * nums[i]));
dp2[i] = min(nums[i], min(dp1[i - 1] * nums[i], dp2[i - 1] * nums[i]));
ans = max(dp1[i], ans);
}
return ans;
}
};416. 分割等和子集
- dp
- 首先判断是否可以分割子集
- 用 cnt 记录 nums 所有数之和
- 如果 cnt 为奇数,说明不存在任何一种方案满足题意
- 如果 cnt 为偶数,说明可能存在方案,那么我们只需要在子集中凑出一个 cnt / 2 即可
- 设 dp 数组,dp[i] 表示数字 i 是否可以被凑出,最多只需要凑到 cnt / 2 即满足题意
- 遍历 nums 数组,对于 nums[i]
- 从 cnt / 2 开始枚举 j ,直到 cnt / 2 < nums[i]
- 判断 dp[j] 是否可以凑出,即由 dp[j - nums[i]] 得到
- 那么我们需要更新 dp[j] = (dp[j] || dp[j - nums[i]])
- 若 j 从 1 开始枚举,可能会将上一轮 nums[i - 1] 的答案覆盖,因此需要倒序枚举 j
- 初始化 dp[0] = 1
class Solution {
public boolean canPartition(int[] nums) {
int cnt = 0;
for (int p : nums) cnt += p;
if ((cnt & 1) == 1) return false;
cnt /= 2;
final int N = 10001;
boolean[] dp = new boolean[N];
dp[0] = true;
for (int i = 0; i < nums.length; i ++) {
for (int j = cnt; j >= nums[i]; j --) {
dp[j] = (dp[j] || dp[j - nums[i]]);
}
}
return dp[cnt];
}
}class Solution {
public:
bool canPartition(vector<int>& nums) {
int cnt = 0;
for (auto p : nums) cnt += p;
if (cnt & 1 == 1) return 0;
cnt /= 2;
const int N = 100001;
bool dp[N] = {0};
dp[0] = 1;
for (int i = 0; i < nums.size(); i ++) {
for (int j = cnt; j >= nums[i]; j --) {
dp[j] = (dp[j] || dp[j - nums[i]]);
}
}
return dp[cnt];
}
};32. 最长有效括号
- 贪心
- 设 l 为
(的数量,r 为)的数量 - 首先从 0 遍历 s:
- 分别记录 l 和 r 的数量
- 若 l == r,说明已经匹配,则更新答案
- 否则若 r > l,说明缺乏
(,重置 l 和 r 为 0
- 再次从末尾开始遍历 s:
- 分别记录 l 和 r 的数量
- 若 l == r,说明已经匹配,则更新答案
- 否则若 l > r,说明缺乏
),重置 l 和 r 为 0
class Solution {
public int longestValidParentheses(String s) {
int l = 0, r = 0, ans = 0;
for (int i = 0; i < s.length(); i ++) {
if (s.charAt(i) == '(') l ++;
else r ++;
if (l == r) ans = Math.max(ans, l << 1);
if (r > l) l = r = 0;
}
l = r = 0;
for (int i = s.length() - 1; i >= 0; i --) {
if (s.charAt(i) == '(') l ++;
else r ++;
if (l == r) ans = Math.max(ans, l << 1);
if (l > r) l = r = 0;
}
return ans;
}
}class Solution {
public:
int longestValidParentheses(string s) {
int l = 0, r = 0, ans = 0;
for (int i = 0; i < s.size(); i ++) {
if (s[i] == '(') l ++;
else r ++;
if (r == l) ans = max(ans, l << 1);
if (r > l) r = l = 0;
}
l = r = 0;
for (int i = s.size() - 1; i >= 0; i --) {
if (s[i] == '(') l ++;
else r ++;
if (r == l) ans = max(ans, l << 1);
if (l > r) r = l = 0;
}
return ans;
}
};62. 不同路径
- dp
- 设 dp 数组,
dp[i][j]表示到达第 i 行,第 j 列的路径数量 - 则,
dp[i][j] = dp[i - 1][j] + dp[i][j - 1] - 初始化第一列和第一行都为 1
class Solution {
public int uniquePaths(int m, int n) {
int[][] dp = new int[m + 1][n + 1];
for (int i = 1; i <= m; i ++) dp[i][1] = 1;
for (int j = 1; j <= n; j ++) dp[1][j] = 1;
for (int i = 2; i <= m; i ++) {
for (int j = 2; j <= n; j ++) {
dp[i][j] = dp[i - 1][j] + dp[i][j - 1];
}
}
return dp[m][n];
}
}class Solution {
public:
int uniquePaths(int m, int n) {
const int N = 101;
int dp[N][N];
for (int i = 1; i <= m; i ++) dp[i][1] = 1;
for (int j = 1; j <= n; j ++) dp[1][j] = 1;
for (int i = 2; i <= m; i ++) {
for (int j = 2; j <= n; j ++) {
dp[i][j] = dp[i - 1][j] + dp[i][j - 1];
}
}
return dp[m][n];
}
};64. 最小路径和
-
dp
-
思想和不同路径类似,不过需要累计数字
-
设 dp 数组,
dp[i][j]表示到达第 i 行第 j 列所累计的最小数字 -
遍历 grid,对于
grid[i][j]:- 可以通过
dp[i - 1][j] + grid[i][j]得到 - 可以通过
dp[i][j - 1] + grid[i][j]得到 - 因此,
dp[i][j]需要取上述两种方案的最小值
- 可以通过
-
初始化,
dp[i][0]列和dp[0][j]行为累加
class Solution {
public int minPathSum(int[][] grid) {
int n = grid.length;
int m = grid[0].length;
int[][] dp = new int[n][m];
dp[0][0] = grid[0][0];
for (int i = 1; i < n; i ++) {
dp[i][0] = dp[i - 1][0] + grid[i][0];
}
for (int j = 1; j < m; j ++) {
dp[0][j] = dp[0][j - 1] + grid[0][j];
}
for (int i = 1; i < n; i ++) {
for (int j = 1; j < m; j ++) {
dp[i][j] = Math.min(dp[i - 1][j], dp[i][j - 1]) + grid[i][j];
}
}
return dp[n - 1][m - 1];
}
}class Solution {
public:
int minPathSum(vector<vector<int>>& grid) {
int n = grid.size();
int m = grid[0].size();
const int N = 2001;
int dp[N][N] = {0};
dp[0][0] = grid[0][0];
for (int i = 1; i < n; i ++) dp[i][0] = dp[i - 1][0] + grid[i][0];
for (int j = 1; j < m; j ++) dp[0][j] = dp[0][j - 1] + grid[0][j];
for (int i = 1; i < n; i ++) {
for (int j = 1; j < m; j ++) {
dp[i][j] = min(dp[i - 1][j], dp[i][j - 1]) + grid[i][j];
}
}
return dp[n - 1][m - 1];
}
};5. 最长回文子串
- 模拟
- 横向左右扩展,找到最长的字串更新
- 遍历 s,对于 s[i]:
- 以该位置作为奇数的中心点,分别向左右扩展
- 以该位置作为偶数的偏向左中心点,分别向左右扩展
- 记录最多能扩展到的位置的下标,更新最长区间
- 答案即为起始下标和结尾下标的字串
class Solution {
int[] check(int l, int r, String s) {
while (l >= 0 && r < s.length() && s.charAt(l) == s.charAt(r)) {
l --; r ++;
}
return new int[]{l + 1, r - 1};
}
public String longestPalindrome(String s) {
int l = 0, r = 0;
for (int i = 0; i < s.length(); i ++) {
// 奇数扩
int[] a = check(i - 1, i + 1, s);
if (a[1] - a[0] > r - l) {
l = a[0]; r = a[1];
}
// 偶数扩
int[] b = check(i, i + 1, s);
if (b[1] - b[0] > r - l) {
l = b[0]; r = b[1];
}
}
return s.substring(l, r + 1);
}
}class Solution {
public:
pair<int, int> check(int l, int r, string & s) {
while (l >= 0 && r < s.size() && s[l] == s[r]) {
l --, r ++;
}
return {l + 1, r - 1};
}
string longestPalindrome(string s) {
int l = 0, r = 0;
for (int i = 0; i < s.size(); i ++) {
// 奇数扩
auto [x1, y1] = check(i - 1, i + 1, s);
if (y1 - x1 > r - l) l = x1, r = y1;
// 偶数扩
auto [x2, y2] = check(i, i + 1, s);
if (y2 - x2 > r - l) l = x2, r = y2;
}
return s.substr(l, r - l + 1);
}
};1143. 最长公共子序列
- dp
- 设 dp 数组,
dp[i][j]表示以 i 结尾的字串和以 j 结尾的字串最长的公共子序列长度 - 遍历 text1,对于 text1[i]:
- 遍历 text2
- 如果 text1[i] == text2[j],则说明
dp[i][j]可以在dp[i - 1][j - 1]的基础上延长 1 - 否则,需要更新
dp[i][j]长度为Math.max(dp[i - 1][j], d[i][j - 1])
- 初始化
dp[0][0] = 0
class Solution {
public int longestCommonSubsequence(String text1, String text2) {
int n = text1.length(); int m = text2.length();
int[][] dp = new int[n + 1][m + 1];
for (int i = 1; i <= n; i ++) {
for (int j = 1; j <= m; j ++) {
if (text1.charAt(i - 1) == text2.charAt(j - 1)) {
dp[i][j] = dp[i - 1][j - 1] + 1;
} else {
dp[i][j] = Math.max(dp[i - 1][j], dp[i][j - 1]);
}
}
}
return dp[n][m];
}
}class Solution {
public:
int longestCommonSubsequence(string text1, string text2) {
int n = text1.size(), m = text2.size();
vector<vector<int>> dp(n + 1, vector<int>(m + 1, 0));
for (int i = 1; i <= n; i ++) {
for (int j = 1; j <= m; j ++) {
if (text1[i - 1] == text2[j - 1]) {
dp[i][j] = dp[i - 1][j - 1] + 1;
} else {
dp[i][j] = max(dp[i - 1][j], dp[i][j - 1]);
}
}
}
return dp[n][m];
}
};72. 编辑距离
-
dp
-
设 dp 数组,其中
dp[i][j]表示将word1的前i个字符转换为word2的前j个字符所需的最少操作数 -
遍历 word1,对于 word[i] 遍历 word2
-
如果
word1[i - 1] == word2[j - 1],表示两个字符相同,不需要进行操作,所以dp[i][j] = dp[i - 1][j - 1]。 -
如果
word1[i - 1] != word2[j - 1],则可以通过三种操作将word1的前i个字符转换为word2的前j个字符:- 替换:将
word1[i - 1]替换为word2[j - 1],操作次数为dp[i - 1][j - 1] + 1 - 删除:删除
word1[i - 1],操作次数为dp[i - 1][j] + 1 - 插入:将
word2[j - 1]插入到word1的末尾,操作次数为dp[i][j - 1] + 1
- 替换:将
-
选择三者中的最小值,
dp[i][j] = min(dp[i - 1][j - 1], dp[i - 1][j], dp[i][j - 1]) + 1 -
初始化
dp[i][0] = dp[i - 1][0] + 1,dp[0][j] = dp[0][j - 1] + 1
class Solution {
public int minDistance(String word1, String word2) {
int n = word1.length(); int m = word2.length();
int[][] dp = new int[n + 1][m + 1];
for (int i = 1; i <= n; i ++) dp[i][0] = dp[i - 1][0] + 1;
for (int j = 1; j <= m; j ++) dp[0][j] = dp[0][j - 1] + 1;
for (int i = 1; i <= n; i ++) {
for (int j = 1; j <= m; j ++) {
if (word1.charAt(i - 1) == word2.charAt(j - 1)) {
dp[i][j] = dp[i - 1][j - 1];
} else {
dp[i][j] = Math.min(dp[i - 1][j - 1], Math.min(dp[i - 1][j], dp[i][j - 1])) + 1;
}
}
}
return dp[n][m];
}
}class Solution {
public:
int minDistance(string word1, string word2) {
int n = word1.size(), m = word2.size();
vector<vector<int>> dp(n + 1, vector<int>(m + 1, 0));
for (int i = 1; i <= n; i ++) dp[i][0] = dp[i - 1][0] + 1;
for (int j = 1; j <= m; j ++) dp[0][j] = dp[0][j - 1] + 1;
for (int i = 1; i <= n; i ++) {
for (int j = 1; j <= m; j ++) {
if (word1[i - 1] == word2[j - 1]) dp[i][j] = dp[i - 1][j - 1];
else {
dp[i][j] = min(dp[i - 1][j - 1], min(dp[i - 1][j], dp[i][j - 1])) + 1;
}
}
}
return dp[n][m];
}
};136. 只出现一次的数字
- 位运算
- 由于数字出现为偶数次,因此通过异或运算可以将相同的数字消去
- 最后剩下的数字即为只出现一次的数字
class Solution {
public int singleNumber(int[] nums) {
int ans = 0;
for (int p : nums) {
ans ^= p;
}
return ans;
}
}class Solution {
public:
int singleNumber(vector<int>& nums) {
int ans = 0;
for (int p : nums) {
ans ^= p;
}
return ans;
}
};169. 多数元素
- Boyer-Moore 投票算法
- 维护一个 res 为候选数,用 cnt 记录数量
- 遍历 nums,对于 nums[i]:
- 若 cnt == 0,则更新 res 为 nums[i]
- 若 res == nums[i],则 cnt ++,反之 cnt --
- 遍历完 nums 后,res 即为答案
- 这个方法的正确性在于数组中有超过 n / 2 的数是同一个数,因此 cnt -- 操作的是和候选众数不相等的数量
class Solution {
public int majorityElement(int[] nums) {
int res = nums[0], cnt = 0;
for (int p : nums) {
if (cnt == 0) res = p;
if (p == res) cnt ++;
else cnt --;
}
return res;
}
}class Solution {
public:
int majorityElement(vector<int>& nums) {
int res = nums[0], cnt = 0;
for (int p : nums) {
if (cnt == 0) res = p;
if (p == res) cnt ++;
else cnt --;
}
return res;
}
};75. 颜色分类
- 双指针
- 设指针 l 左边都为 0,r 指针的右边都为 2,l 和 r 中间的都为 0
- 初始化 l = 0,r = nums.length() - 1
- 用 idx = 0 开始遍历,遍历的终点为右指针 r,对于 nums[idx]:
- 若 nums[idx] == 1,应该将 nums [idx] 移动到 l 的左边,即交换 nums[l] 和 nums[idx],之后 l ++,idx ++
- 若 nums[idx] == 2,应该将 nums [idx] 移动到 r 的右边,即交换 nums[r] 和 nums[idx],之后 r --,idx 保持不变
- 其他情况 idx ++
- 交换 r 后 idx 保持不变是因为有可能交换过来的 nums[r] = 0,因此需要在下一轮继续判断
class Solution {
public void sortColors(int[] nums) {
int l = 0, r = nums.length - 1, idx = 0;
while (idx <= r) {
if (nums[idx] == 0) {
int t = nums[l];
nums[l ++] = nums[idx];
nums[idx ++] = t;
}
else if (nums[idx] == 2) {
int t = nums[r];
nums[r --] = nums[idx];
nums[idx ++] = t;
} else {
idx ++;
}
}
}
}class Solution {
public:
void sortColors(vector<int>& nums) {
int l = 0, r = nums.size() - 1, idx = 0;
while (idx <= r) {
if (nums[idx] == 0) {
// 将 0 左移
swap(nums[l ++], nums[idx ++]);
}
else if (nums[idx] == 2) {
// 将 2 右移
swap(nums[r --], nums[idx]);
} else {
idx ++;
}
}
}
};31. 下一个排列
- 排列
- 原理就是
C++中的next_permutation函数,生成指定序列的下一个全排列 - 从给定序列的最右端开始,找到第一个满足
nums[i] < nums[i + 1]的元素nums[i]- 若找不到这样的元素
nums[i]:说明当前序列是最后一个排列,函数将序列重排为第一个排列,并返回false - 若找到了元素
nums[i]:继续从最右端开始,找到第一个满足nums[i] < nums[j]的元素nums[j]。
- 若找不到这样的元素
- 交换
nums[i]和nums[j],然后从i + 1开始将序列反转,使得它们按照升序排列。
class Solution {
public void nextPermutation(int[] nums) {
int i = nums.length - 2;
while (i >= 0 && nums[i] >= nums[i + 1]) {
i --;
}
if (i >= 0) {
int j = nums.length - 1;
// 从后向前找到第一个比 nums[i] 大的元素
while (nums[j] <= nums[i]) j --;
swap(nums, i, j); // 交换 i和 j
}
// 反转 i 之后的所有元素
reverse(nums, i + 1, nums.length - 1);
}
void swap(int[] nums, int i, int j) {
int t = nums[i];
nums[i] = nums[j];
nums[j] = t;
}
void reverse(int[] nums, int l, int r) {
while (l < r) {
swap(nums, l ++, r --);
}
}
}class Solution {
public:
void nextPermutation(vector<int>& nums) {
int i = nums.size() - 2; // 从倒数第二个元素开始
// 从后向前找到第一个递减的元素
while (i >= 0 && nums[i] >= nums[i + 1]) i --;
if (i >= 0) {
int j = nums.size() - 1;
// 从后向前找到第一个比 nums[i] 大的元素
while (nums[j] <= nums[i]) j --;
swap(nums[i], nums[j]); // 交换 i和 j
}
// 反转 i 之后的所有元素
reverse(nums.begin() + i + 1, nums.end());
}
};287. 寻找重复数
-
快慢指针
-
初始化
- 定义两个指针
l和r,初始值为nums[0] - 将数组中的数字范围和数组长度的特性可以看作一个链表,其中存在环,并且环的入口就是重复的数字
- 定义两个指针
-
第一阶段:找到环中的一个相遇点
l是慢指针,每次走一步,即l = nums[l]r是快指针,每次走两步,即r = nums[nums[r]]- 由于数组中存在重复元素,根据鸽巢原理,必定会形成环
- 当快慢指针相遇时,说明已经进入环中,循环结束
-
第二阶段:找到环的入口
- 在第一阶段找到环中的某个位置后,将慢指针
l重新指向数组开头nums[0] - 然后让两个指针每次都走一步,直到再次相遇
- 此时相遇的位置即为环的入口,也就是数组中重复的那个数字
- 在第一阶段找到环中的某个位置后,将慢指针
-
返回结果
- 当慢指针和快指针再次相遇时,返回此位置的值,它就是数组中重复的数字
class Solution {
public int findDuplicate(int[] nums) {
int l = nums[0], r = nums[0];
while (true) {
l = nums[l];
r = nums[nums[r]];
if (l == r) {
break;
}
}
l = nums[0];
while (l != r) {
l = nums[l];
r = nums[r];
}
return l;
}
}class Solution {
public:
int findDuplicate(vector<int>& nums) {
int l = nums[0], r = nums[0];
// 第一次相遇:找到环中的一个位置
while (1) {
l = nums[l]; // 慢指针每次走一步
r = nums[nums[r]]; // 快指针每次走两步
if (l == r) {
break; // 找到环中的相遇点
}
}
// 第二次相遇:找到环的入口,也就是重复的数字
l = nums[0];
while (l != r) {
l = nums[l];
r = nums[r];
}
return l;
}
};