提出关系模型的是美国 IBM 公司的 E.F.Codd:
- 1970年提出关系数据模型,之后,提出了关系代数和关系演算的概念。
- 1972年提出了关系的第一、第二、第三范式。
- 1974年提出了关系的
BC范式。
2.1 关系数据结构及形式化定义
按照数据模型的三个要素:
- 关系模型由关系数据结构;
- 关系操作集合;
- 关系完整性约束三部分组成。
下面将对这三部分内容进行分别介绍。
2.1.1 关系
关系模型的数据结构非常简单,只包含单一的数据结构—关系。在用户看来,关系模型中数据的逻辑结构是一张扁平的二维表。
域
- 是一组具有相同数据类型的值的集合。
- 例如:自然数、整数、实数的集合。
笛卡尔积
- 给定一组域:$D_1, D_2, D_3, \dots, D_n$,且允许其中某些域是相同的
- 则其笛卡尔积为:$D_1 \times D_2 \times D_n \times \dots \times D_n = { (d_1, d_2, d_3 \dots, d_n)\ | \ d_i \in D_i, i = 1, 2, \dots , n }$。
- 其中每一个元素 $(d_1, d_2, d_3 \dots, d_n)$ 叫做一个 $n$ 元组,或简称元组,其中 $d_i$ 为分量。
一个域允许的不同取值个数称为这个域的基数:
- 若 $D_i (i = 1, 2, \dots, n)$ 为有限集,其基数为 $m_i(i = 1, 2, \dots, n)$
- 则 \[D_1 \times D_2 \times D_n \times \dots \times D_n\] 的基数 \[M = \prod^{n}_{i = 1}m_i\]。
笛卡尔积可以表示为一张二维表,表中的每行对应一个元组,表中的每一列的值来自一个域。
例如:
-
已知:$D_1 = X = \set{ a, b }, D_2 = Y = \set{ c, d }$
-
则 $D_1 \times D_2$ 的笛卡尔积为 $D_1 \times D_2 = \set{ (a, c), (a, d), (b, c), (b, d) }$
-
笛卡尔基数为 $2 \times 2 = 4$,共 $4$ 个元组,可生成表格如下:
-
$X$ $Y$ $a$ $c$ $a$ $d$ $b$ $c$ $b$ $d$
关系
-
$D_1 \times D_2 \times D_n \times \dots \times D_n$ 的子集叫做在域 $D_1, D_2, D_3, \dots, D_n$ 上的关系。
-
表示为 $R(D_1, D_2, D_3, \dots, D_n)$,其中 $R$ 为关系名,$n$ 为关系的目或度(Degree)。
-
关系中的每个元素是关系中的元组,通常用 $t$ 表示。
-
当 $n = 1$ 时,称该关系为单元关系(Unary relation)或一元关系,$n = 2$ 时称为二元关系(Binary relation)。
关系是笛卡儿积的有限子集,所以关系也是一张二维表,表的每行对应一个元组,表的每列对应一个域。
码
-
候选码(Candidate key):若关系中的某一属性组的值能唯一地标识一个元组,而其子集不能,则称该属性组为候选码(如学号,身份证号)。
-
全码(All key):在最简单的情况下,候选码只包含一个属性。在最极端的情况下,关系模式的所有属性是这个关系模式的候选码。
-
主码(Primary key):若一个关系有多个候选码,则选定其中一个为主码。候选码的诸属性称为主属性(Prime attribute)。不包含在任何侯选码中的属性称为非码属性或非主属性(Non-key attribute)。
主码和候选码本质相同,只是数量不同。
三类关系
- 基本关系(基本表或基表):实际存在的表,是实际存储数据的逻辑表示。
- 查询表:查询结果对应的表。
- 视图表:由基本表或其他视图表导出的表,是虚表,不对应实际存储的数据。
基本关系的性质
- 列同质的(Homogeneous)每一列中的分量是同一类型的数据,来自同一个域。
- 不同的列可出自同一个域:
- 其中的每一列称为一个属性。
- 不同的属性要给予不同的属性名。
- 列的顺序无所谓(属性名打破有序性)。
- 任意两个元组不能完全相同(候选码不同)。
- 行的顺序无所谓,即行的次序可以任意交换。
- 分量必须取原子值,每一个分量都必须是不可分的数据项。这是规范条件中最基本的。
2.1.2 关系模式
在数据库中要区分型和值,关系数据库中:
- 关系模式(Relation Schema)是型,关系是值。
关系模式是对关系的描述:
-
元组集合的结构:
- 属性构成
- 属性来自的域
- 属性与域之间的映象关系
-
完整性约束条件,元组语义。
关系的描述称为关系模式(relation schema)。它可以形式化地表示为 $R(U, D, DOM, F)$:
-
$R$ 为关系名
-
$U$ 为组成该关系的属性名集合
-
$D$ 为 $U$ 中属性所来自的域
-
$DOM$ 为属性向域的映像集合
-
$F$ 为属性间数据的依赖关系集合。
2.1.3 关系数据库
在关系模型中,实体以及实体间的联系都是用关系来表示的。在一个给定的应用领域中,所有关系的集合构成一个关系数据库。
关系数据库也有型和值之分:
- 关系数据库的型也称为关系数据库模式,是对关系数据库的描述。
- 关系数据库模式包括若干域的定义,以及在这些域上定义的若干关系模式。
- 关系数据库的值是这些关系模式在某一时刻对应的关系的集合,通常就称为关系数据库。
2.1.4 关系模型的存储结构
- 有的关系数据库管理系统中一个表对应一个操作系统文件,将物理数据组织交给操作系统完成。
- 有的关系数据库管理系统从操作系统那里申请若干个大的文件,自己划分文件空间,组织表、索引等存储结构,并进行存储管理。
2.2 关系操作
2.2.1 基本的关系操作
- 查询:
- 基本操作:选择、投影、并、差、笛卡尔积;
- 其他操作:连接、除、交,可由上述基本操作导出。
- 数据更新:插入、删除、修改。
关系操作的特点是集合操作方式:
- 操作的对象和结果都是集合。
- 这种操作方式也称为一次一集合(set-at-a-time)的方式。
相应地,非关系数据模型的数据操作方式则为一次一记录(record-at-a-time)的方式。
2.2.2 关系数据语言的分类

特点:
- 关系语言是一种高度非过程化的语言,存取路径的选择由
DBMS的优化机制来完成,用户不必用循环结构就可以完成数据操作。 - 能够嵌入高级语言中使用。
- 关系代数、元组关系演算和域关系演算三种语言在表达能力上完全等价。
2.3 关系的完整性
关系模型中有三类完整性约束:
-
实体完整性(entity integrity)
-
参照完整性(referential integrity)
-
用户定义的完整性(user-defined integrity)。
关系模型必须满足实体完整性和参照完整性,被称作是关系的两个不变性,应该由关系系统自动支持。
用户定义的完整性是应用领域需要遵循的约束条件,体现了具体领域中的语义约束。
2.3.1 实体完整性
- 若属性(指一个或一组属性)$A$ 是基本关系 $R$ 的主属性,则 $A$ 不能取空值(null value)。
- 所谓空值就是“不知道”或“不存在”或“无意义”的值。
原因:
- 实体完整性规则是针对基本关系而言的。一个基本表通常对应现实世界的一个实体集。
- 现实世界中的实体是可区分的,即它们具有某种唯一性标识。
- 关系模型中以主码作为唯一性标识。
- 主码中的属性即主属性不能取空值。主属性取空值,就说明存在某个不可标识的实体,即存在不可区分的实体,这与第(2)点相矛盾,因此这个规则称为实体完整性。
2.3.2 参照完整性
外码:
- 设 $F$ 是基本关系 $R$ 的一个或一组属性,但不是关系 $R$ 的码,
- 如果 $F$ 与基本关系 $S$ 的主码 $K_s$ 相对应,则称 $F$ 是 $R$ 的外码。
- 基本关系 $R$ 称为参照关系(Referencing Relation)
- 基本关系 $S$ 称为被参照关系(Referenced Relation)或目标关系(Target Relation)
关系 $R$ 和 $S$ 不一定是不同的关系,目标关系 $S$ 的主码 $K_s$ 和参照关系的外码 $F$ 必须定义在同一个(或一组)域上。
外码并不一定要与相应的主码同名;当外码与相应的主码属于不同关系时,往往取相同的名字,以便于识别。
参照完整性规则:
- 若属性(或属性组)$F$ 是基本关系 $R$ 的外码,它与基本关系 $S$ 的主码 $K$ 相对应(基本关系 $R$ 和 $S$ 不一定是不同的关系)
- 则对于 $R$ 中每个元组在 $F$ 上的值必须:
- 取空值($F$ 的每个属性值均为空值)
- 或等于 $S$ 中某个元组的主码值
2.3.3 用户定义的完整性
- 用户定义的完整性是针对某一具体关系数据库的约束条件,反映某一具体应用所涉及的数据必须满足的语义要求。
- 关系模型应提供定义和检验这类完整性的机制,以便用统一的系统的方法处理它们,而不要由应用程序承担这一功能。
2.4 关系代数
关系代数是一种抽象的查询语言,它用对关系的运算来表达查询。
运算具备以下要偶素:
- 运算对象
- 运算符
- 运算结果
任何一种运算都是将一定的运算符作用于一定的运算对象上,得到预期的运算结果。
关系代数的运算对象是关系,运算结果亦为关系。关系代数用到的运算符包括两类:
- 集合运算符
- 专门的关系运算符

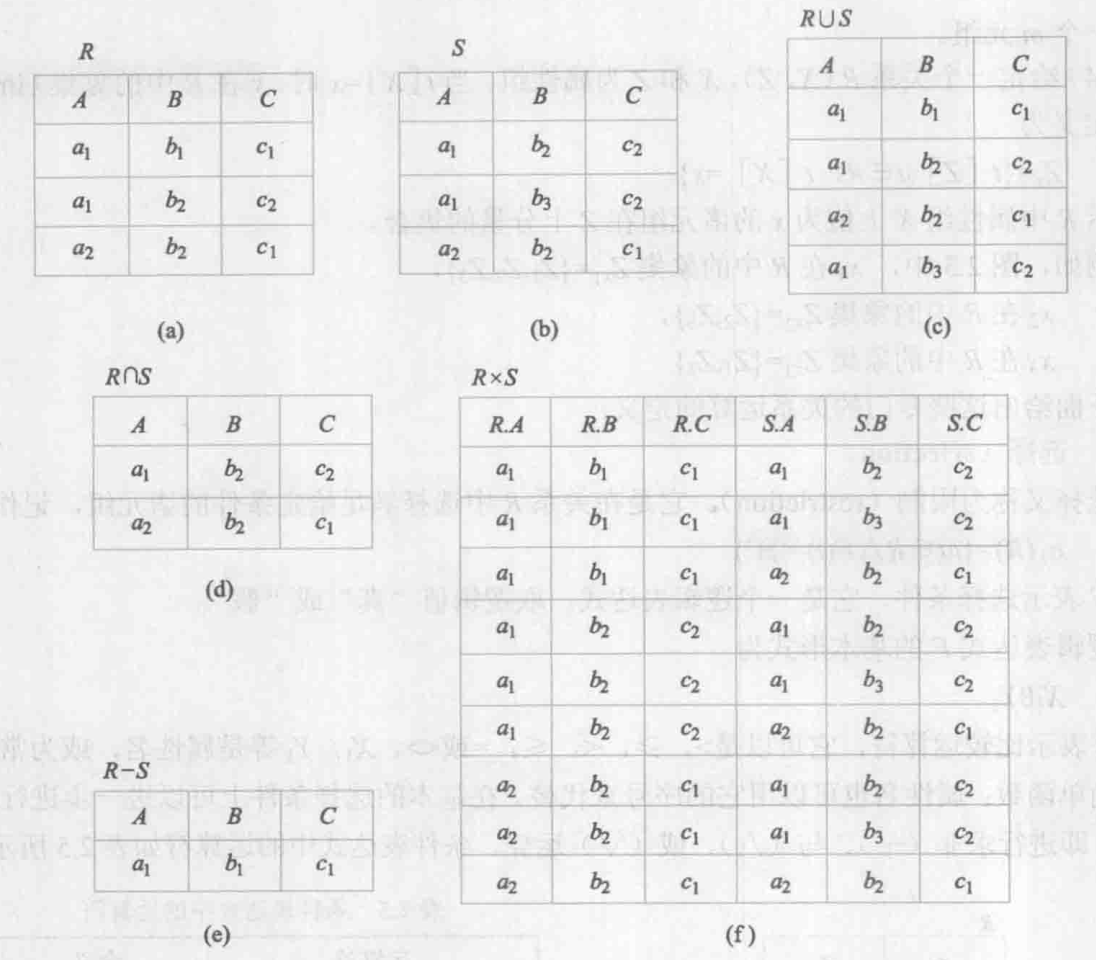
2.4.1 传统的集合运算
传统的集合运算是二目运算,包括并、差、交、笛卡儿积4种运算。
设关系 $R$ 和关系 $S$ 具有相同的目(即两个关系都有 $n$ 个属性),且相应的属性取自同一个域,$t$ 是元组变量,$t \in R$ 表示 $t$ 是 $R$ 的一个元组。可以定义并、差、交、笛卡儿积运算如下:
- 并(union):
- 关系 $R$ 与关系 $S$ 的并记作: \[R \cup S = \{t |t \in R \land t \in S \}\]
- 其结果仍为 $n$ 目关系,由属于 $R$ 或属于 $S$ 的元组组成。
- 差(except):
- 关系 $R$ 与关系 $S$ 的差记作:\[R - S = \{ t | t \in R \land t \notin S \}\]
- 其结果关系仍为 $n$ 目关系,由属于 $R$ 而不属于 $S$ 的所有元组组成。
- 交(intersection):
- 关系 $R$ 与关系 $S$ 的交记作 \[R \cap S = \{ t | t \in R \land t \in S \}\]
- 其结果关系仍为 $n$ 目关系,由既属于 $R$ 又属于 $S$ 的元组组成。
- 关系的交可以用差来表示,即 \[R \cap S = R - ( R - S )\]。
- 笛卡儿积(cartesian product):
- 这里笛卡儿积的元素是元组。
- 两个分别为 $n$ 目和 $m$ 目的关系 $R$ 和 $S$ 的笛卡儿积是一个 $(n + m)$ 列的元组的集合。元组的前 $n$ 列是关系 $R$ 的一个元组,后 $m$ 列是关系 $S$ 的一个元组。
- 若 $R$ 有个元组,$S$ 有 $2$ 个元组,则关系 $R$ 和关系 $S$ 的笛卡儿积有 $k_1 \times k_2$ 个元组。记作 \[R \times S = \{\overset{\frown}{t_r t_s} | t_r \in R \land t_s \in S \}\]
2.4.2 专门的关系运算
专门的关系运算包括选择、投影、连接、除运算等。为了叙述上的方便,先引入几个记号:
- $R$,$t \in R$,$t[A_i]$
- 设关系模式为 $R(A_1, A_2, \dots , A_n)$
- 它的一个关系设为 $R$
- $t \in R$ 表示 $t$ 是 $R$ 的一个元组
- $t[A_i]$ 表示元组 $t$ 中相应于属性 $A_i$ 的一个分量
- $A$,$t[A]$,$\overline{A}$
- 若 \[A = \{ A_{i1}, A_{i2}, \dots , A_{ik} \}\],其中 \[A_{i1}, A_{i2}, \dots , A_{ik}\] 是 \[A_1, A_2, \dots , A_n\] 中的一部分,则 $A$ 被称为属性列或属性组。
- \[t[A] = (t[A_{i1}], t[A_{i2}], \dots , t[A_{ik}])\] 表示元组 $t$ 在属性列$A$ 上诸分量的集合。
- \[\overline{A}\] 则表示 \[\{ A_1, A_2, \dots , A_n \}\] 中去掉 \[A_{i1}, A_{i2}, \dots , A_{ik}\] 后剩余的属性组。
- $\overset{\frown}{t_r t_s}$
- $R$ 为 $n$ 目关系,$S$ 为 $m$ 目关系
- $t_r \in R$,$t_s \in S$, $\overset{\frown}{t_r t_s}$ 称为元组的连接
- $\overset{\frown}{t_r t_s}$ 是一个 $n + m$ 列的元组,前 $n$ 个分量为 $R$ 中的一个 $n$ 元组,后 $m$ 个分量为 $S$ 中的一个 $m$ 元组
- 象集 $Z_x$
- 给定一个关系 $R(X, Z)$, $X$ 和 $Z$ 为属性组
- 当 $t[X] = x$ 时,$x$ 在 $R$ 中的象集(Images Set) 为:$Z_x = \set{ t[Z] | t\in R, t[X] = x }$
- 它表示 $R$ 中属性组 $X$ 上值为 $x$ 的诸元组在 $Z$ 上分量的集合。
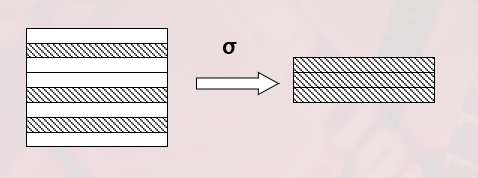
选择
- 选择又称为限制(Restriction)
- 选择运算符的含义:
- 在关系R中选择满足给定条件的诸元组
- \[\sigma_F(R) = \{ t | t \in R \land F(t) = `true' \}\]
- $F$:选择条件,是一个逻辑表达式,取值为“真”或“假”
- 基本形式为:$X_1 \theta Y_1$
- $\theta$ 表示比较运算符,它可以是 $\gt, \ge, \lt, \le, =, \ne$。
- $X_1, Y_1$ 等是属性名、常量、简单函数;属性名也可以用它的序号来代替;
- 在基本的选择条件上可以进一步进行逻辑运算,求非 ,与,或运算。
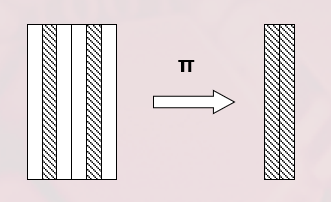
投影
- 从 $R$ 中选择出若干属性列组成新的关系
- $\Pi_A(R) = { t[A] | t \in R }$
- $A$ :$R$ 中的属性
- 投影操作主要是从列的角度进行运算
- 投影之后不仅取消了原关系中的某些列,而且还可能取消某些元组(避免重复行)
连接
- 连接也称为 $\theta$ 连接
- 连接运算的含义:
- 从两个关系的笛卡尔积中选取属性间满足一定条件的元组
- \[R \underset{A \theta B}{\bowtie} S = \{ \overset{\frown}{t_r t_s} | t_r \in R \land t_s \in S \land t_r[A] \theta t_s[B] \}\]
- $A$ 和 $B$ :分别为 $R$ 和 $S$ 上度数相等且可比的属性组
- 连接运算从 $R$ 和 $S$ 的广义笛卡尔积 $R \times S$ 中选取 $R$ 关系在 $A$ 属性组上的值与 $S$ 关系在 $B$ 属性组上的值满足比较关系 $\theta$ 的元组
两类常用连接运算:
- 等值连接(equijoin):
- $\theta$ 为 $=$ 的运算
- 从关系 $R$ 与 $S$ 的广义笛卡尔积中选取 $A,B$ 属性值相等的那些元组
- \[R \underset{A = B}{\bowtie} S = \{ \overset{\frown}{t_r t_s} | t_r \in R \land t_s \in S \land t_r[A] \theta t_s[B] \}\]
- 自然连接(natural join):
- 自然连接是一种特殊的等值连接:
- 两个关系中进行比较的分量必须是相同的属性组
- 在结果中把重复的属性列去掉
- 自然连接的含义:
- $R$ 和 $S$ 具有相同的属性组 $B$
- \[R \bowtie S = \{ \overset{\frown}{t_r t_s} [U-B] | t_r \in R \land t_s \in S \land t_r[B] = t_s[B] \}\]
一般的连接操作是从行的角度进行运算。
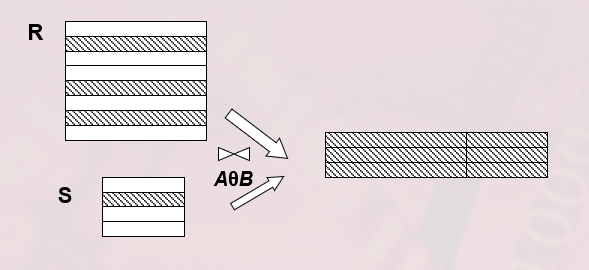
自然连接还需要取消重复列,所以是同时从行和列的角度进行运算。
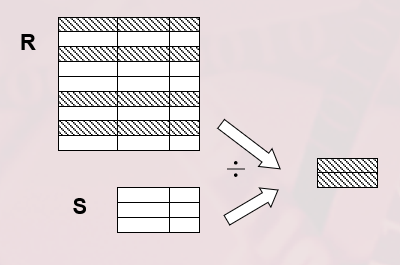
除运算
- 给定关系 $R(X, Y)$ 和 $S(Y, Z)$,其中 $X, Y, Z$ 为属性组。
- $R$ 中的 $Y$ 与 $S$ 中的 $Y$ 可以有不同的属性名,但必须出自相同的域集。
- $R$ 与 $S$ 的除运算得到一个新的关系 $P(X)$
- $P$ 是 $R$ 中满足下列条件的元组在 $X$ 属性列上的投影:
- 元组在 $X$ 上分量值 $x$ 的象集 $Y_x$ 包含 $S$ 在 $Y$ 上投影的集合
- \[R \div S = \{ t_r[X] | t_r \in R \land \Pi_Y(S) \subseteq Y_x \}\]
- $Y_x$ :$x$ 在 $R$ 中的象集,$x = t_r[X]$
除操作是同时从行和列角度进行运算